Java 基础
Java 基础 - 面向对象
三大特性
封装
利用抽象数据类型将数据和基于数据的操作封装在一起,使其构成一个不可分割的独立实体。数据被保护在抽象数据类型的内部,尽可能地隐藏内部的细节,只保留一些对外接口使之与外部发生联系。用户无需知道对象内部的细节,但可以通过对象对外提供的接口来访问该对象。
优点:
- 减少耦合: 可以独立地开发、测试、优化、使用、理解和修改
- 减轻维护的负担: 可以更容易被程序员理解,并且在调试的时候可以不影响其他模块
- 有效地调节性能: 可以通过剖析确定哪些模块影响了系统的性能
- 提高软件的可重用性
- 降低了构建大型系统的风险: 即使整个系统不可用,但是这些独立的模块却有可能是可用的
以下 Person 类封装 name、gender、age 等属性,外界只能通过 get() 方法获取一个 Person 对象的 name 属性和 gender 属性,而无法获取 age 属性,但是 age 属性可以供 work() 方法使用。
注意到 gender 属性使用 int 数据类型进行存储,封装使得用户注意不到这种实现细节。并且在需要修改 gender 属性使用的数据类型时,也可以在不影响客户端代码的情况下进行。
public class Person {
private String name;
private int gender;
private int age;
public String getName() {
return name;
}
public String getGender() {
return gender == 0 ? "man" : "woman";
}
public void work() {
if (18 <= age && age <= 50) {
System.out.println(name + " is working very hard!");
} else {
System.out.println(name + " can't work any more!");
}
}
}
继承
继承实现了 IS-A 关系,例如 Cat 和 Animal 就是一种 IS-A 关系,因此 Cat 可以继承自 Animal,从而获得 Animal 非 private 的属性和方法。
继承应该遵循里氏替换原则,子类对象必须能够替换掉所有父类对象。
Cat 可以当做 Animal 来使用,也就是说可以使用 Animal 引用 Cat 对象。父类引用指向子类对象称为 向上转型 。
Animal animal = new Cat();
多态
多态分为编译时多态和运行时多态:
- 编译时多态主要指方法的重载
- 运行时多态指程序中定义的对象引用所指向的具体类型在运行期间才确定
运行时多态有三个条件:
- 继承
- 覆盖(重写)
- 向上转型
下面的代码中,乐器类(Instrument)有两个子类: Wind 和 Percussion,它们都覆盖了父类的 play() 方法,并且在 main() 方法中使用父类 Instrument 来引用 Wind 和 Percussion 对象。在 Instrument 引用调用 play() 方法时,会执行实际引用对象所在类的 play() 方法,而不是 Instrument 类的方法。
public class Instrument {
public void play() {
System.out.println("Instrument is playing...");
}
}
public class Wind extends Instrument {
public void play() {
System.out.println("Wind is playing...");
}
}
public class Percussion extends Instrument {
public void play() {
System.out.println("Percussion is playing...");
}
}
public class Music {
public static void main(String[] args) {
List<Instrument> instruments = new ArrayList<>();
instruments.add(new Wind());
instruments.add(new Percussion());
for(Instrument instrument : instruments) {
instrument.play();
}
}
}
Java 基础 - 知识点
数据类型
包装类型
八个基本类型:
- boolean/1
- byte/8
- char/16
- short/16
- int/32
- float/32
- long/64
- double/64
基本类型都有对应的包装类型,基本类型与其对应的包装类型之间的赋值使用自动装箱与拆箱完成。
Integer x = 2; // 装箱
int y = x; // 拆箱
缓存池
new Integer(123) 与 Integer.valueOf(123) 的区别在于:
- new Integer(123) 每次都会新建一个对象
- Integer.valueOf(123) 会使用缓存池中的对象,多次调用会取得同一个对象的引用。
Integer x = new Integer(123);
Integer y = new Integer(123);
System.out.println(x == y); // false
Integer z = Integer.valueOf(123);
Integer k = Integer.valueOf(123);
System.out.println(z == k); // true
valueOf() 方法的实现比较简单,就是先判断值是否在缓存池中,如果在的话就直接返回缓存池的内容。
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
在 Java 8 中,Integer 缓存池的大小默认为 -128~127。
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
编译器会在缓冲池范围内的基本类型自动装箱过程调用 valueOf() 方法,因此多个 Integer 实例使用自动装箱来创建并且值相同,那么就会引用相同的对象。
Integer m = 123;
Integer n = 123;
System.out.println(m == n); // true
基本类型对应的缓冲池如下:
- boolean values true and false
- all byte values
- short values between -128 and 127
- int values between -128 and 127
- char in the range \u0000 to \u007F
在使用这些基本类型对应的包装类型时,就可以直接使用缓冲池中的对象。
如果在缓冲池之外:
Integer m = 323;
Integer n = 323;
System.out.println(m == n); // false
String
概览
String 被声明为 final,因此它不可被继承。
内部使用 char 数组存储数据,该数组被声明为 final,这意味着 value 数组初始化之后就不能再引用其它数组。并且 String 内部没有改变 value 数组的方法,因此可以保证 String 不可变。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
不可变的好处
1. 可以缓存 hash 值
因为 String 的 hash 值经常被使用,例如 String 用做 HashMap 的 key。不可变的特性可以使得 hash 值也不可变,因此只需要进行一次计算。
2. String Pool 的需要
如果一个 String 对象已经被创建过了,那么就会从 String Pool 中取得引用。只有 String 是不可变的,才可能使用 String Pool。
3. 安全性
String 经常作为参数,String 不可变性可以保证参数不可变。例如在作为网络连接参数的情况下如果 String 是可变的,那么在网络连接过程中,String 被改变,改变 String 对象的那一方以为现在连接的是其它主机,而实际情况却不一定是。
4. 线程安全
String 不可变性天生具备线程安全,可以在多个线程中安全地使用。
String, StringBuffer and StringBuilder
1. 可变性
- String 不可变
- StringBuffer 和 StringBuilder 可变
2. 线程安全
- String 不可变,因此是线程安全的
- StringBuilder 不是线程安全的
- StringBuffer 是线程安全的,内部使用 synchronized 进行同步
String.intern()
使用 String.intern() 可以保证相同内容的字符串变量引用同一的内存对象。
下面示例中,s1 和 s2 采用 new String() 的方式新建了两个不同对象,而 s3 是通过 s1.intern() 方法取得一个对象引用。intern() 首先把 s1 引用的对象放到 String Pool(字符串常量池)中,然后返回这个对象引用。因此 s3 和 s1 引用的是同一个字符串常量池的对象。
String s1 = new String("aaa");
String s2 = new String("aaa");
System.out.println(s1 == s2); // false
String s3 = s1.intern();
System.out.println(s1.intern() == s3); // true
如果是采用 "bbb" 这种使用双引号的形式创建字符串实例,会自动地将新建的对象放入 String Pool 中。
String s4 = "bbb";
String s5 = "bbb";
System.out.println(s4 == s5); // true
- HotSpot中字符串常量池保存哪里?永久代?方法区还是堆区?
- 运行时常量池(Runtime Constant Pool)是虚拟机规范中是方法区的一部分,在加载类和结构到虚拟机后,就会创建对应的运行时常量池;而字符串常量池是这个过程中常量字符串的存放位置。所以从这个角度,字符串常量池属于虚拟机规范中的方法区,它是一个逻辑上的概念;而堆区,永久代以及元空间是实际的存放位置。
- 不同的虚拟机对虚拟机的规范(比如方法区)是不一样的,只有 HotSpot 才有永久代的概念。
- HotSpot也是发展的,由于一些问题在新窗口打开的存在,HotSpot考虑逐渐去永久代,对于不同版本的JDK,实际的存储位置是有差异的,具体看如下表格:
| JDK版本 | 是否有永久代,字符串常量池放在哪里? | 方法区逻辑上规范,由哪些实际的部分实现的? |
|---|---|---|
| jdk1.6及之前 | 有永久代,运行时常量池(包括字符串常量池),静态变量存放在永久代上 | 这个时期方法区在HotSpot中是由永久代来实现的,以至于这个时期说方法区就是指永久代 |
| jdk1.7 | 有永久代,但已经逐步“去永久代”,字符串常量池、静态变量移除,保存在堆中; | 这个时期方法区在HotSpot中由永久代(类型信息、字段、方法、常量)和堆(字符串常量池、静态变量)共同实现 |
| jdk1.8及之后 | 取消永久代,类型信息、字段、方法、常量保存在本地内存的元空间,但字符串常量池、静态变量仍在堆中 | 这个时期方法区在HotSpot中由本地内存的元空间(类型信息、字段、方法、常量)和堆(字符串常量池、静态变量)共同实现 |
运算
参数传递
Java 的参数是以值传递的形式传入方法中,而不是引用传递。
以下代码中 Dog dog 的 dog 是一个指针,存储的是对象的地址。在将一个参数传入一个方法时,本质上是将对象的地址以值的方式传递到形参中。因此在方法中改变指针引用的对象,那么这两个指针此时指向的是完全不同的对象,一方改变其所指向对象的内容对另一方没有影响。
public class Dog {
String name;
Dog(String name) {
this.name = name;
}
String getName() {
return this.name;
}
void setName(String name) {
this.name = name;
}
String getObjectAddress() {
return super.toString();
}
}
public class PassByValueExample {
public static void main(String[] args) {
Dog dog = new Dog("A");
System.out.println(dog.getObjectAddress()); // Dog@4554617c
func(dog);
System.out.println(dog.getObjectAddress()); // Dog@4554617c
System.out.println(dog.getName()); // A
}
private static void func(Dog dog) {
System.out.println(dog.getObjectAddress()); // Dog@4554617c
dog = new Dog("B");
System.out.println(dog.getObjectAddress()); // Dog@74a14482
System.out.println(dog.getName()); // B
}
}
但是如果在方法中改变对象的字段值会改变原对象该字段值,因为改变的是同一个地址指向的内容。
class PassByValueExample {
public static void main(String[] args) {
Dog dog = new Dog("A");
func(dog);
System.out.println(dog.getName()); // B
}
private static void func(Dog dog) {
dog.setName("B");
}
}
float 与 double
1.1 字面量属于 double 类型,不能直接将 1.1 直接赋值给 float 变量,因为这是向下转型。Java 不能隐式执行向下转型,因为这会使得精度降低。
// float f = 1.1;
1.1f 字面量才是 float 类型。
float f = 1.1f;
隐式类型转换
因为字面量 1 是 int 类型,它比 short 类型精度要高,因此不能隐式地将 int 类型下转型为 short 类型。
short s1 = 1;
// s1 = s1 + 1;
但是使用 += 运算符可以执行隐式类型转换。
s1 += 1;
上面的语句相当于将 s1 + 1 的计算结果进行了向下转型:
s1 = (short) (s1 + 1);
switch
从 Java 7 开始,可以在 switch 条件判断语句中使用 String 对象。
String s = "a";
switch (s) {
case "a":
System.out.println("aaa");
break;
case "b":
System.out.println("bbb");
break;
}
switch 不支持 long,是因为 switch 的设计初衷是对那些只有少数的几个值进行等值判断,如果值过于复杂,那么还是用 if 比较合适。
// long x = 111;
// switch (x) { // Incompatible types. Found: 'long', required: 'char, byte, short, int, Character, Byte, Short, Integer, String, or an enum'
// case 111:
// System.out.println(111);
// break;
// case 222:
// System.out.println(222);
// break;
// }
继承
访问权限
Java 中有三个访问权限修饰符: private、protected 以及 public,如果不加访问修饰符,表示包级可见。
可以对类或类中的成员(字段以及方法)加上访问修饰符。
- 类可见表示其它类可以用这个类创建实例对象。
- 成员可见表示其它类可以用这个类的实例对象访问到该成员;
protected 用于修饰成员,表示在继承体系中成员对于子类可见,但是这个访问修饰符对于类没有意义。
设计良好的模块会隐藏所有的实现细节,把它的 API 与它的实现清晰地隔离开来。模块之间只通过它们的 API 进行通信,一个模块不需要知道其他模块的内部工作情况,这个概念被称为信息隐藏或封装。因此访问权限应当尽可能地使每个类或者成员不被外界访问。
如果子类的方法重写了父类的方法,那么子类中该方法的访问级别不允许低于父类的访问级别。这是为了确保可以使用父类实例的地方都可以使用子类实例,也就是确保满足里氏替换原则。
字段决不能是公有的,因为这么做的话就失去了对这个字段修改行为的控制,客户端可以对其随意修改。例如下面的例子中,AccessExample 拥有 id 共有字段,如果在某个时刻,我们想要使用 int 去存储 id 字段,那么就需要去修改所有的客户端代码。
public class AccessExample {
public String id;
}
可以使用公有的 getter 和 setter 方法来替换公有字段,这样的话就可以控制对字段的修改行为。
public class AccessExample {
private int id;
public String getId() {
return id + "";
}
public void setId(String id) {
this.id = Integer.valueOf(id);
}
}
但是也有例外,如果是包级私有的类或者私有的嵌套类,那么直接暴露成员不会有特别大的影响。
public class AccessWithInnerClassExample {
private class InnerClass {
int x;
}
private InnerClass innerClass;
public AccessWithInnerClassExample() {
innerClass = new InnerClass();
}
public int getValue() {
return innerClass.x; // 直接访问
}
}
抽象类与接口
1. 抽象类
抽象类和抽象方法都使用 abstract 关键字进行声明。抽象类一般会包含抽象方法,抽象方法一定位于抽象类中。
抽象类和普通类最大的区别是,抽象类不能被实例化,需要继承抽象类才能实例化其子类。
public abstract class AbstractClassExample {
protected int x;
private int y;
public abstract void func1();
public void func2() {
System.out.println("func2");
}
}
public class AbstractExtendClassExample extends AbstractClassExample {
@Override
public void func1() {
System.out.println("func1");
}
}
// AbstractClassExample ac1 = new AbstractClassExample(); // 'AbstractClassExample' is abstract; cannot be instantiated
AbstractClassExample ac2 = new AbstractExtendClassExample();
ac2.func1();
2. 接口
接口是抽象类的延伸,在 Java 8 之前,它可以看成是一个完全抽象的类,也就是说它不能有任何的方法实现。
从 Java 8 开始,接口也可以拥有默认的方法实现,这是因为不支持默认方法的接口的维护成本太高了。在 Java 8 之前,如果一个接口想要添加新的方法,那么要修改所有实现了该接口的类。
接口的成员(字段 + 方法)默认都是 public 的,并且不允许定义为 private 或者 protected。
接口的字段默认都是 static 和 final 的。
public interface InterfaceExample {
void func1();
default void func2(){
System.out.println("func2");
}
int x = 123;
// int y; // Variable 'y' might not have been initialized
public int z = 0; // Modifier 'public' is redundant for interface fields
// private int k = 0; // Modifier 'private' not allowed here
// protected int l = 0; // Modifier 'protected' not allowed here
// private void fun3(); // Modifier 'private' not allowed here
}
public class InterfaceImplementExample implements InterfaceExample {
@Override
public void func1() {
System.out.println("func1");
}
}
// InterfaceExample ie1 = new InterfaceExample(); // 'InterfaceExample' is abstract; cannot be instantiated
InterfaceExample ie2 = new InterfaceImplementExample();
ie2.func1();
System.out.println(InterfaceExample.x);
3. 比较
- 从设计层面上看,抽象类提供了一种 IS-A 关系,那么就必须满足里式替换原则,即子类对象必须能够替换掉所有父类对象。而接口更像是一种 LIKE-A 关系,它只是提供一种方法实现契约,并不要求接口和实现接口的类具有 IS-A 关系。
- 从使用上来看,一个类可以实现多个接口,但是不能继承多个抽象类。
- 接口的字段只能是 static 和 final 类型的,而抽象类的字段没有这种限制。
- 接口的成员只能是 public 的,而抽象类的成员可以有多种访问权限。
4. 使用选择
使用接口:
- 需要让不相关的类都实现一个方法,例如不相关的类都可以实现 Compareable 接口中的 compareTo() 方法;
- 需要使用多重继承。
使用抽象类:
- 需要在几个相关的类中共享代码。
- 需要能控制继承来的成员的访问权限,而不是都为 public。
- 需要继承非静态和非常量字段。
在很多情况下,接口优先于抽象类,因为接口没有抽象类严格的类层次结构要求,可以灵活地为一个类添加行为。并且从 Java 8 开始,接口也可以有默认的方法实现,使得修改接口的成本也变的很低。
super
- 访问父类的构造函数: 可以使用 super() 函数访问父类的构造函数,从而委托父类完成一些初始化的工作。
- 访问父类的成员: 如果子类重写了父类的中某个方法的实现,可以通过使用 super 关键字来引用父类的方法实现。
public class SuperExample {
protected int x;
protected int y;
public SuperExample(int x, int y) {
this.x = x;
this.y = y;
}
public void func() {
System.out.println("SuperExample.func()");
}
}
public class SuperExtendExample extends SuperExample {
private int z;
public SuperExtendExample(int x, int y, int z) {
super(x, y);
this.z = z;
}
@Override
public void func() {
super.func();
System.out.println("SuperExtendExample.func()");
}
}
SuperExample e = new SuperExtendExample(1, 2, 3);
e.func();
SuperExample.func()
SuperExtendExample.func()
重写与重载
1. 重写(Override)
存在于继承体系中,指子类实现了一个与父类在方法声明上完全相同的一个方法。
为了满足里式替换原则,重写有以下两个限制:
- 子类方法的访问权限必须大于等于父类方法;
- 子类方法的返回类型必须是父类方法返回类型或为其子类型。
使用 @Override 注解,可以让编译器帮忙检查是否满足上面的两个限制条件。
2. 重载(Overload)
存在于同一个类中,指一个方法与已经存在的方法名称上相同,但是参数类型、个数、顺序至少有一个不同。
应该注意的是,返回值不同,其它都相同不算是重载。
Object 通用方法
概览
public final native Class<?> getClass()
public native int hashCode()
public boolean equals(Object obj)
protected native Object clone() throws CloneNotSupportedException
public String toString()
public final native void notify()
public final native void notifyAll()
public final native void wait(long timeout) throws InterruptedException
public final void wait(long timeout, int nanos) throws InterruptedException
public final void wait() throws InterruptedException
protected void finalize() throws Throwable {}
equals()
1. 等价关系
(一)自反性
x.equals(x); // true
(二)对称性
x.equals(y) == y.equals(x); // true
(三)传递性
if (x.equals(y) && y.equals(z))
x.equals(z); // true;
(四)一致性
多次调用 equals() 方法结果不变
x.equals(y) == x.equals(y); // true
(五)与 null 的比较
对任何不是 null 的对象 x 调用 x.equals(null) 结果都为 false
x.equals(null); // false;
2. equals() 与 ==
- 对于基本类型,== 判断两个值是否相等,基本类型没有 equals() 方法。
- 对于引用类型,== 判断两个变量是否引用同一个对象,而 equals() 判断引用的对象是否等价。
Integer x = new Integer(1);
Integer y = new Integer(1);
System.out.println(x.equals(y)); // true
System.out.println(x == y); // false
3. 实现
- 检查是否为同一个对象的引用,如果是直接返回 true;
- 检查是否是同一个类型,如果不是,直接返回 false;
- 将 Object 对象进行转型;
- 判断每个关键域是否相等。
public class EqualExample {
private int x;
private int y;
private int z;
public EqualExample(int x, int y, int z) {
this.x = x;
this.y = y;
this.z = z;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
EqualExample that = (EqualExample) o;
if (x != that.x) return false;
if (y != that.y) return false;
return z == that.z;
}
}
hashCode()
hashCode() 返回散列值,而 equals() 是用来判断两个对象是否等价。等价的两个对象散列值一定相同,但是散列值相同的两个对象不一定等价。
在覆盖 equals() 方法时应当总是覆盖 hashCode() 方法,保证等价的两个对象散列值也相等。
下面的代码中,新建了两个等价的对象,并将它们添加到 HashSet 中。我们希望将这两个对象当成一样的,只在集合中添加一个对象,但是因为 EqualExample 没有实现 hasCode() 方法,因此这两个对象的散列值是不同的,最终导致集合添加了两个等价的对象。
EqualExample e1 = new EqualExample(1, 1, 1);
EqualExample e2 = new EqualExample(1, 1, 1);
System.out.println(e1.equals(e2)); // true
HashSet<EqualExample> set = new HashSet<>();
set.add(e1);
set.add(e2);
System.out.println(set.size()); // 2
理想的散列函数应当具有均匀性,即不相等的对象应当均匀分布到所有可能的散列值上。这就要求了散列函数要把所有域的值都考虑进来,可以将每个域都当成 R 进制的某一位,然后组成一个 R 进制的整数。R 一般取 31,因为它是一个奇素数,如果是偶数的话,当出现乘法溢出,信息就会丢失,因为与 2 相乘相当于向左移一位。
一个数与 31 相乘可以转换成移位和减法: 31*x == (x<<5)-x,编译器会自动进行这个优化。
@Override
public int hashCode() {
int result = 17;
result = 31 * result + x;
result = 31 * result + y;
result = 31 * result + z;
return result;
}
toString()
默认返回 ToStringExample@4554617c 这种形式,其中 @ 后面的数值为散列码的无符号十六进制表示。
public class ToStringExample {
private int number;
public ToStringExample(int number) {
this.number = number;
}
}
ToStringExample example = new ToStringExample(123);
System.out.println(example.toString());
ToStringExample@4554617c
clone()
1. cloneable
clone() 是 Object 的 protected 方法,它不是 public,一个类不显式去重写 clone(),其它类就不能直接去调用该类实例的 clone() 方法。
public class CloneExample {
private int a;
private int b;
}
CloneExample e1 = new CloneExample();
// CloneExample e2 = e1.clone(); // 'clone()' has protected access in 'java.lang.Object'
重写 clone() 得到以下实现:
public class CloneExample {
private int a;
private int b;
@Override
protected CloneExample clone() throws CloneNotSupportedException {
return (CloneExample)super.clone();
}
}
CloneExample e1 = new CloneExample();
try {
CloneExample e2 = e1.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
java.lang.CloneNotSupportedException: CloneExample
以上抛出了 CloneNotSupportedException,这是因为 CloneExample 没有实现 Cloneable 接口。
应该注意的是,clone() 方法并不是 Cloneable 接口的方法,而是 Object 的一个 protected 方法。Cloneable 接口只是规定,如果一个类没有实现 Cloneable 接口又调用了 clone() 方法,就会抛出 CloneNotSupportedException。
public class CloneExample implements Cloneable {
private int a;
private int b;
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
2. 浅拷贝
拷贝对象和原始对象的引用类型引用同一个对象。
public class ShallowCloneExample implements Cloneable {
private int[] arr;
public ShallowCloneExample() {
arr = new int[10];
for (int i = 0; i < arr.length; i++) {
arr[i] = i;
}
}
public void set(int index, int value) {
arr[index] = value;
}
public int get(int index) {
return arr[index];
}
@Override
protected ShallowCloneExample clone() throws CloneNotSupportedException {
return (ShallowCloneExample) super.clone();
}
}
ShallowCloneExample e1 = new ShallowCloneExample();
ShallowCloneExample e2 = null;
try {
e2 = e1.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
e1.set(2, 222);
System.out.println(e2.get(2)); // 222
3. 深拷贝
拷贝对象和原始对象的引用类型引用不同对象。
public class DeepCloneExample implements Cloneable {
private int[] arr;
public DeepCloneExample() {
arr = new int[10];
for (int i = 0; i < arr.length; i++) {
arr[i] = i;
}
}
public void set(int index, int value) {
arr[index] = value;
}
public int get(int index) {
return arr[index];
}
@Override
protected DeepCloneExample clone() throws CloneNotSupportedException {
DeepCloneExample result = (DeepCloneExample) super.clone();
result.arr = new int[arr.length];
for (int i = 0; i < arr.length; i++) {
result.arr[i] = arr[i];
}
return result;
}
}
DeepCloneExample e1 = new DeepCloneExample();
DeepCloneExample e2 = null;
try {
e2 = e1.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
e1.set(2, 222);
System.out.println(e2.get(2)); // 2
4. clone() 的替代方案
使用 clone() 方法来拷贝一个对象即复杂又有风险,它会抛出异常,并且还需要类型转换。Effective Java 书上讲到,最好不要去使用 clone(),可以使用拷贝构造函数或者拷贝工厂来拷贝一个对象。
public class CloneConstructorExample {
private int[] arr;
public CloneConstructorExample() {
arr = new int[10];
for (int i = 0; i < arr.length; i++) {
arr[i] = i;
}
}
public CloneConstructorExample(CloneConstructorExample original) {
arr = new int[original.arr.length];
for (int i = 0; i < original.arr.length; i++) {
arr[i] = original.arr[i];
}
}
public void set(int index, int value) {
arr[index] = value;
}
public int get(int index) {
return arr[index];
}
}
CloneConstructorExample e1 = new CloneConstructorExample();
CloneConstructorExample e2 = new CloneConstructorExample(e1);
e1.set(2, 222);
System.out.println(e2.get(2)); // 2
关键字
final
1. 数据
声明数据为常量,可以是编译时常量,也可以是在运行时被初始化后不能被改变的常量。
- 对于基本类型,final 使数值不变;
- 对于引用类型,final 使引用不变,也就不能引用其它对象,但是被引用的对象本身是可以修改的。
final int x = 1;
// x = 2; // cannot assign value to final variable 'x'
final A y = new A();
y.a = 1;
2. 方法
声明方法不能被子类重写。
private 方法隐式地被指定为 final,如果在子类中定义的方法和基类中的一个 private 方法签名相同,此时子类的方法不是重写基类方法,而是在子类中定义了一个新的方法。
3. 类
声明类不允许被继承。
static
1. 静态变量
- 静态变量: 又称为类变量,也就是说这个变量属于类的,类所有的实例都共享静态变量,可以直接通过类名来访问它;静态变量在内存中只存在一份。
- 实例变量: 每创建一个实例就会产生一个实例变量,它与该实例同生共死。
public class A {
private int x; // 实例变量
private static int y; // 静态变量
public static void main(String[] args) {
// int x = A.x; // Non-static field 'x' cannot be referenced from a static context
A a = new A();
int x = a.x;
int y = A.y;
}
}
2. 静态方法
静态方法在类加载的时候就存在了,它不依赖于任何实例。所以静态方法必须有实现,也就是说它不能是抽象方法(abstract)。
public abstract class A {
public static void func1(){
}
// public abstract static void func2(); // Illegal combination of modifiers: 'abstract' and 'static'
}
只能访问所属类的静态字段和静态方法,方法中不能有 this 和 super 关键字。
public class A {
private static int x;
private int y;
public static void func1(){
int a = x;
// int b = y; // Non-static field 'y' cannot be referenced from a static context
// int b = this.y; // 'A.this' cannot be referenced from a static context
}
}
3. 静态语句块
静态语句块在类初始化时运行一次。
public class A {
static {
System.out.println("123");
}
public static void main(String[] args) {
A a1 = new A();
A a2 = new A();
}
}
123
4. 静态内部类
非静态内部类依赖于外部类的实例,而静态内部类不需要。
public class OuterClass {
class InnerClass {
}
static class StaticInnerClass {
}
public static void main(String[] args) {
// InnerClass innerClass = new InnerClass(); // 'OuterClass.this' cannot be referenced from a static context
OuterClass outerClass = new OuterClass();
InnerClass innerClass = outerClass.new InnerClass();
StaticInnerClass staticInnerClass = new StaticInnerClass();
}
}
静态内部类不能访问外部类的非静态的变量和方法。
5. 静态导包
在使用静态变量和方法时不用再指明 ClassName,从而简化代码,但可读性大大降低。
import static com.xxx.ClassName.*
6. 初始化顺序
静态变量和静态语句块优先于实例变量和普通语句块,静态变量和静态语句块的初始化顺序取决于它们在代码中的顺序。
public static String staticField = "静态变量";
static {
System.out.println("静态语句块");
}
public String field = "实例变量";
{
System.out.println("普通语句块");
}
最后才是构造函数的初始化。
public InitialOrderTest() {
System.out.println("构造函数");
}
存在继承的情况下,初始化顺序为:
- 父类(静态变量、静态语句块)
- 子类(静态变量、静态语句块)
- 父类(实例变量、普通语句块)
- 父类(构造函数)
- 子类(实例变量、普通语句块)
- 子类(构造函数)
反射
每个类都有一个 Class 对象,包含了与类有关的信息。当编译一个新类时,会产生一个同名的 .class 文件,该文件内容保存着 Class 对象。
类加载相当于 Class 对象的加载。类在第一次使用时才动态加载到 JVM 中,可以使用 Class.forName("com.mysql.jdbc.Driver") 这种方式来控制类的加载,该方法会返回一个 Class 对象。
反射可以提供运行时的类信息,并且这个类可以在运行时才加载进来,甚至在编译时期该类的 .class 不存在也可以加载进来。
Class 和 java.lang.reflect 一起对反射提供了支持,java.lang.reflect 类库主要包含了以下三个类:
- Field : 可以使用 get() 和 set() 方法读取和修改 Field 对象关联的字段;
- Method : 可以使用 invoke() 方法调用与 Method 对象关联的方法;
- Constructor : 可以用 Constructor 创建新的对象。
Advantages of Using Reflection:
- Extensibility Features : An application may make use of external, user-defined classes by creating instances of extensibility objects using their fully-qualified names.
- Class Browsers and Visual Development Environments : A class browser needs to be able to enumerate the members of classes. Visual development environments can benefit from making use of type information available in reflection to aid the developer in writing correct code.
- Debuggers and Test Tools : Debuggers need to be able to examine private members on classes. Test harnesses can make use of reflection to systematically call a discoverable set APIs defined on a class, to insure a high level of code coverage in a test suite.
Drawbacks of Reflection:
Reflection is powerful, but should not be used indiscriminately. If it is possible to perform an operation without using reflection, then it is preferable to avoid using it. The following concerns should be kept in mind when accessing code via reflection.
- Performance Overhead : Because reflection involves types that are dynamically resolved, certain Java virtual machine optimizations can not be performed. Consequently, reflective operations have slower performance than their non-reflective counterparts, and should be avoided in sections of code which are called frequently in performance-sensitive applications.
- Security Restrictions : Reflection requires a runtime permission which may not be present when running under a security manager. This is in an important consideration for code which has to run in a restricted security context, such as in an Applet.
- Exposure of Internals :Since reflection allows code to perform operations that would be illegal in non-reflective code, such as accessing private fields and methods, the use of reflection can result in unexpected side-effects, which may render code dysfunctional and may destroy portability. Reflective code breaks abstractions and therefore may change behavior with upgrades of the platform.
异常
Throwable 可以用来表示任何可以作为异常抛出的类,分为两种: Error 和 Exception。其中 Error 用来表示 JVM 无法处理的错误,Exception 分为两种:
- 受检异常 : 需要用 try...catch... 语句捕获并进行处理,并且可以从异常中恢复;
- 非受检异常 : 是程序运行时错误,例如除 0 会引发 Arithmetic Exception,此时程序崩溃并且无法恢复。
泛型
public class Box<T> {
// T stands for "Type"
private T t;
public void set(T t) { this.t = t; }
public T get() { return t; }
}
注解
Java 注解是附加在代码中的一些元信息,用于一些工具在编译、运行时进行解析和使用,起到说明、配置的功能。注解不会也不能影响代码的实际逻辑,仅仅起到辅助性的作用。
特性
Java 各版本的新特性
New highlights in Java SE 8
- Lambda Expressions
- Pipelines and Streams
- Date and Time API
- Default Methods
- Type Annotations
- Nashhorn JavaScript Engine
- Concurrent Accumulators
- Parallel operations
- PermGen Error Removed
New highlights in Java SE 7
- Strings in Switch Statement
- Type Inference for Generic Instance Creation
- Multiple Exception Handling
- Support for Dynamic Languages
- Try with Resources
- Java nio Package
- Binary Literals, Underscore in literals
- Diamond Syntax
Java 与 C++ 的区别
- Java 是纯粹的面向对象语言,所有的对象都继承自 java.lang.Object,C++ 为了兼容 C 即支持面向对象也支持面向过程。
- Java 通过虚拟机从而实现跨平台特性,但是 C++ 依赖于特定的平台。
- Java 没有指针,它的引用可以理解为安全指针,而 C++ 具有和 C 一样的指针。
- Java 支持自动垃圾回收,而 C++ 需要手动回收。
- Java 不支持多重继承,只能通过实现多个接口来达到相同目的,而 C++ 支持多重继承。
- Java 不支持操作符重载,虽然可以对两个 String 对象支持加法运算,但是这是语言内置支持的操作,不属于操作符重载,而 C++ 可以。
- Java 的 goto 是保留字,但是不可用,C++ 可以使用 goto。
- Java 不支持条件编译,C++ 通过 #ifdef #ifndef 等预处理命令从而实现条件编译。
What are the main differences between Java and C++?在新窗口打开
JRE or JDK
- JRE is the JVM program, Java application need to run on JRE.
- JDK is a superset of JRE, JRE + tools for developing java programs. e.g, it provides the compiler "javac"
Java 基础 - 图谱 & Q/A
知识体系
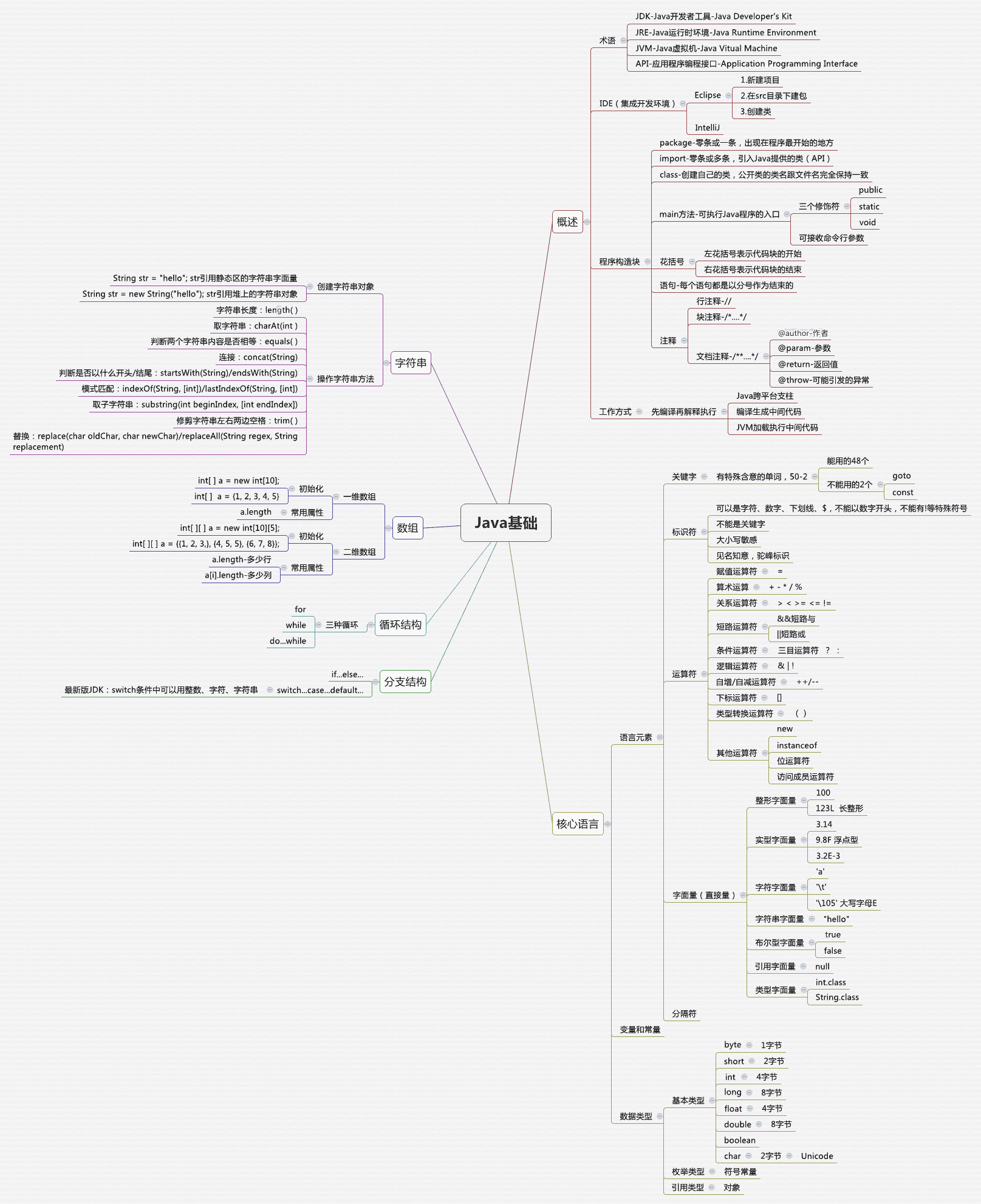
Q&A
Java 中应该使用什么数据类型来代表价格?
如果不是特别关心内存和性能的话,使用BigDecimal,否则使用预定义精度的 double 类型。
怎么将 byte 转换为 String?
可以使用 String 接收 byte[] 参数的构造器来进行转换,需要注意的点是要使用的正确的编码,否则会使用平台默认编码,这个编码可能跟原来的编码相同,也可能不同。
Java 中怎样将 bytes 转换为 long 类型?
String接收bytes的构造器转成String,再Long.parseLong
我们能将 int 强制转换为 byte 类型的变量吗? 如果该值大于 byte 类型的范围,将会出现什么现象?
是的,我们可以做强制转换,但是 Java 中 int 是 32 位的,而 byte 是 8 位的,所以,如果强制转化是,int 类型的高 24 位将会被丢弃,byte 类型的范围是从 -128 到 127。
存在两个类,B 继承 A,C 继承 B,我们能将 B 转换为 C 么? 如 C = (C) B;
可以,向下转型。但是不建议使用,容易出现类型转型异常.
哪个类包含 clone 方法? 是 Cloneable 还是 Object?
java.lang.Cloneable 是一个标示性接口,不包含任何方法,clone 方法在 object 类中定义。并且需要知道 clone() 方法是一个本地方法,这意味着它是由 c 或 c++ 或 其他本地语言实现的。
Java 中 ++ 操作符是线程安全的吗?
不是线程安全的操作。它涉及到多个指令,如读取变量值,增加,然后存储回内存,这个过程可能会出现多个线程交差。还会存在竞态条件(读取-修改-写入)。
a = a + b 与 a += b 的区别
+= 隐式的将加操作的结果类型强制转换为持有结果的类型。如果两个整型相加,如 byte、short 或者 int,首先会将它们提升到 int 类型,然后在执行加法操作。
byte a = 127;
byte b = 127;
b = a + b; // error : cannot convert from int to byte
b += a; // ok
(因为 a+b 操作会将 a、b 提升为 int 类型,所以将 int 类型赋值给 byte 就会编译出错)
我能在不进行强制转换的情况下将一个 double 值赋值给 long 类型的变量吗?
不行,你不能在没有强制类型转换的前提下将一个 double 值赋值给 long 类型的变量,因为 double 类型的范围比 long 类型更广,所以必须要进行强制转换。
3*0.1 == 0.3 将会返回什么? true 还是 false?
false,因为有些浮点数不能完全精确的表示出来。
int 和 Integer 哪个会占用更多的内存?
Integer 对象会占用更多的内存。Integer 是一个对象,需要存储对象的元数据。但是 int 是一个原始类型的数据,所以占用的空间更少。
为什么 Java 中的 String 是不可变的(Immutable)?
Java 中的 String 不可变是因为 Java 的设计者认为字符串使用非常频繁,将字符串设置为不可变可以允许多个客户端之间共享相同的字符串。更详细的内容参见答案。
我们能在 Switch 中使用 String 吗?
从 Java 7 开始,我们可以在 switch case 中使用字符串,但这仅仅是一个语法糖。内部实现在 switch 中使用字符串的 hash code。
Java 中的构造器链是什么?
当你从一个构造器中调用另一个构造器,就是Java 中的构造器链。这种情况只在重载了类的构造器的时候才会出现。
枚举类
JDK1.5出现 每个枚举值都需要调用一次构造函数
什么是不可变对象(immutable object)? Java 中怎么创建一个不可变对象?
不可变对象指对象一旦被创建,状态就不能再改变。任何修改都会创建一个新的对象,如 String、Integer及其它包装类。
如何在Java中写出Immutable的类?
要写出这样的类,需要遵循以下几个原则:
1)immutable对象的状态在创建之后就不能发生改变,任何对它的改变都应该产生一个新的对象。
2)Immutable类的所有的属性都应该是final的。
3)对象必须被正确的创建,比如: 对象引用在对象创建过程中不能泄露(leak)。
4)对象应该是final的,以此来限制子类继承父类,以避免子类改变了父类的immutable特性。
5)如果类中包含mutable类对象,那么返回给客户端的时候,返回该对象的一个拷贝,而不是该对象本身(该条可以归为第一条中的一个特例)
我们能创建一个包含可变对象的不可变对象吗?
是的,我们是可以创建一个包含可变对象的不可变对象的,你只需要谨慎一点,不要共享可变对象的引用就可以了,如果需要变化时,就返回原对象的一个拷贝。最常见的例子就是对象中包含一个日期对象的引用。
有没有可能两个不相等的对象有相同的 hashcode?
有可能,两个不相等的对象可能会有相同的 hashcode 值,这就是为什么在 hashmap 中会有冲突。相等 hashcode 值的规定只是说如果两个对象相等,必须有相同的hashcode 值,但是没有关于不相等对象的任何规定。
两个相同的对象会有不同的 hash code 吗?
不能,根据 hash code 的规定,这是不可能的。
我们可以在 hashcode() 中使用随机数字吗?
不行,因为对象的 hashcode 值必须是相同的。
Java 中,Comparator 与 Comparable 有什么不同?
Comparable 接口用于定义对象的自然顺序,而 comparator 通常用于定义用户定制的顺序。Comparable 总是只有一个,但是可以有多个 comparator 来定义对象的顺序。
为什么在重写 equals 方法的时候需要重写 hashCode 方法?
因为有强制的规范指定需要同时重写 hashcode 与 equals 是方法,许多容器类,如 HashMap、HashSet 都依赖于 hashcode 与 equals 的规定。
“a==b”和”a.equals(b)”有什么区别?
如果 a 和 b 都是对象,则 a==b 是比较两个对象的引用,只有当 a 和 b 指向的是堆中的同一个对象才会返回 true,而 a.equals(b) 是进行逻辑比较,所以通常需要重写该方法来提供逻辑一致性的比较。例如,String 类重写 equals() 方法,所以可以用于两个不同对象,但是包含的字母相同的比较。
a.hashCode() 有什么用? 与 a.equals(b) 有什么关系?
简介: hashCode() 方法是相应对象整型的 hash 值。它常用于基于 hash 的集合类,如 Hashtable、HashMap、LinkedHashMap等等。它与 equals() 方法关系特别紧密。根据 Java 规范,两个使用 equals() 方法来判断相等的对象,必须具有相同的 hash code。
1、hashcode的作用
List和Set,如何保证Set不重复呢? 通过迭代使用equals方法来判断,数据量小还可以接受,数据量大怎么解决? 引入hashcode,实际上hashcode扮演的角色就是寻址,大大减少查询匹配次数。
2、hashcode重要吗
对于数组、List集合就是一个累赘。而对于hashmap, hashset, hashtable就异常重要了。
3、equals方法遵循的原则
- 对称性 若x.equals(y)true,则y.equals(x)true
- 自反性 x.equals(x)必须true
- 传递性 若x.equals(y)true,y.equals(z)true,则x.equals(z)必为true
- 一致性 只要x,y内容不变,无论调用多少次结果不变
- 其他 x.equals(null) 永远false,x.equals(和x数据类型不同)始终false
final、finalize 和 finally 的不同之处?
- final 是一个修饰符,可以修饰变量、方法和类。如果 final 修饰变量,意味着该变量的值在初始化后不能被改变。
- Java 技术允许使用 finalize() 方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。这个方法是由垃圾收集器在确定这个对象没有被引用时对这个对象调用的,但是什么时候调用 finalize 没有保证。
- finally 是一个关键字,与 try 和 catch 一起用于异常的处理。finally 块一定会被执行,无论在 try 块中是否有发生异常。
Java 中的编译期常量是什么? 使用它又什么风险?
变量也就是我们所说的编译期常量,这里的 public 可选的。实际上这些变量在编译时会被替换掉,因为编译器知道这些变量的值,并且知道这些变量在运行时不能改变。这种方式存在的一个问题是你使用了一个内部的或第三方库中的公有编译时常量,但是这个值后面被其他人改变了,但是你的客户端仍然在使用老的值,甚至你已经部署了一个新的jar。为了避免这种情况,当你在更新依赖 JAR 文件时,确保重新编译你的程序。
静态内部类与顶级类有什么区别?
一个公共的顶级类的源文件名称与类名相同,而嵌套静态类没有这个要求。一个嵌套类位于顶级类内部,需要使用顶级类的名称来引用嵌套静态类,如 HashMap.Entry 是一个嵌套静态类,HashMap 是一个顶级类,Entry是一个嵌套静态类。
Java 中,Serializable 与 Externalizable 的区别?
Serializable 接口是一个序列化 Java 类的接口,以便于它们可以在网络上传输或者可以将它们的状态保存在磁盘上,是 JVM 内嵌的默认序列化方式,成本高、脆弱而且不安全。Externalizable 允许你控制整个序列化过程,指定特定的二进制格式,增加安全机制。
说出 JDK 1.7 中的三个新特性?
虽然 JDK 1.7 不像 JDK 5 和 8 一样的大版本,但是,还是有很多新的特性,如 try-with-resource 语句,这样你在使用流或者资源的时候,就不需要手动关闭,Java 会自动关闭。Fork-Join 池某种程度上实现 Java 版的 Map-reduce。允许 Switch 中有 String 变量和文本。菱形操作符(<>)用于泛型推断,不再需要在变量声明的右边申明泛型,因此可以写出可读写更强、更简洁的代码。另一个值得一提的特性是改善异常处理,如允许在同一个 catch 块中捕获多个异常。
说出 5 个 JDK 1.8 引入的新特性?
Java 8 在 Java 历史上是一个开创新的版本,下面 JDK 8 中 5 个主要的特性: Lambda 表达式,允许像对象一样传递匿名函数 Stream API,充分利用现代多核 CPU,可以写出很简洁的代码 Date 与 Time API,最终,有一个稳定、简单的日期和时间库可供你使用 扩展方法,现在,接口中可以有静态、默认方法。 重复注解,现在你可以将相同的注解在同一类型上使用多次。
下述包含 Java 面试过程中关于 SOLID 的设计原则,OOP 基础,如类,对象,接口,继承,多态,封装,抽象以及更高级的一些概念,如组合、聚合及关联。也包含了 GOF 设计模式的问题。
接口是什么? 为什么要使用接口而不是直接使用具体类?
接口用于定义 API。它定义了类必须得遵循的规则。同时,它提供了一种抽象,因为客户端只使用接口,这样可以有多重实现,如 List 接口,你可以使用可随机访问的 ArrayList,也可以使用方便插入和删除的 LinkedList。接口中不允许普通方法,以此来保证抽象,但是 Java 8 中你可以在接口声明静态方法和默认普通方法。
Java 中,抽象类与接口之间有什么不同?
Java 中,抽象类和接口有很多不同之处,但是最重要的一个是 Java 中限制一个类只能继承一个类,但是可以实现多个接口。抽象类可以很好的定义一个家族类的默认行为,而接口能更好的定义类型,有助于后面实现多态机制 参见第六条。
Object有哪些公用方法?
clone equals hashcode wait notify notifyall finalize toString getClass 除了clone和finalize其他均为公共方法。
11个方法,wait被重载了两次
equals与==的区别
区别1. ==是一个运算符 equals是Object类的方法
区别2. 比较时的区别
- 用于基本类型的变量比较时: ==用于比较值是否相等,equals不能直接用于基本数据类型的比较,需要转换为其对应的包装类型。
- 用于引用类型的比较时。==和equals都是比较栈内存中的地址是否相等 。相等为true 否则为false。但是通常会重写equals方法去实现对象内容的比较。
String、StringBuffer与StringBuilder的区别
第一点: 可变和适用范围。String对象是不可变的,而StringBuffer和StringBuilder是可变字符序列。每次对String的操作相当于生成一个新的String对象,而对StringBuffer和StringBuilder的操作是对对象本身的操作,而不会生成新的对象,所以对于频繁改变内容的字符串避免使用String,因为频繁的生成对象将会对系统性能产生影响。
第二点: 线程安全。String由于有final修饰,是immutable的,安全性是简单而纯粹的。StringBuilder和StringBuffer的区别在于StringBuilder不保证同步,也就是说如果需要线程安全需要使用StringBuffer,不需要同步的StringBuilder效率更高。
switch能否用String做参数
Java1.7开始支持,但实际这是一颗Java语法糖。除此之外,byte,short,int,枚举均可用于switch,而boolean和浮点型不可以。
接口与抽象类
- 一个子类只能继承一个抽象类, 但能实现多个接口
- 抽象类可以有构造方法, 接口没有构造方法
- 抽象类可以有普通成员变量, 接口没有普通成员变量
- 抽象类和接口都可有静态成员变量, 抽象类中静态成员变量访问类型任意,接口只能public static final(默认)
- 抽象类可以没有抽象方法, 抽象类可以有普通方法;接口在JDK8之前都是抽象方法,在JDK8可以有default方法,在JDK9中允许有私有普通方法
- 抽象类可以有静态方法;接口在JDK8之前不能有静态方法,在JDK8中可以有静态方法,且只能被接口类直接调用(不能被实现类的对象调用)
- 抽象类中的方法可以是public、protected; 接口方法在JDK8之前只有public abstract,在JDK8可以有default方法,在JDK9中允许有private方法
抽象类和最终类
抽象类可以没有抽象方法, 最终类可以没有最终方法
最终类不能被继承, 最终方法不能被重写(可以重载)
异常
相关的关键字 throw、throws、try...catch、finally
- throws 用在方法签名上, 以便抛出的异常可以被调用者处理
- throw 方法内部通过throw抛出异常
- try 用于检测包住的语句块, 若有异常, catch子句捕获并执行catch块
关于finally
- finally不管有没有异常都要处理
- 当try和catch中有return时,finally仍然会执行,finally比return先执行
- 不管有木有异常抛出, finally在return返回前执行
- finally是在return后面的表达式运算后执行的(此时并没有返回运算后的值,而是先把要返回的值保存起来,管finally中的代码怎么样,返回的值都不会改变,仍然是之前保存的值),所以函数返回值是在finally执行前确定的
注意: finally中最好不要包含return,否则程序会提前退出,返回值不是try或catch中保存的返回值
finally不执行的几种情况: 程序提前终止如调用了System.exit, 病毒,断电
受检查异常和运行时异常
- 受检查的异常(checked exceptions),其必须被try...catch语句块所捕获, 或者在方法签名里通过throws子句声明。受检查的异常必须在编译时被捕捉处理,命名为Checked Exception是因为Java编译器要进行检查, Java虚拟机也要进行检查, 以确保这个规则得到遵守。
常见的checked exception: ClassNotFoundException IOException FileNotFoundException EOFException
- 运行时异常(runtime exceptions), 需要程序员自己分析代码决定是否捕获和处理,比如空指针,被0除...
常见的runtime exception: NullPointerException ArithmeticException ClassCastException IllegalArgumentException IllegalStateException IndexOutOfBoundsException NoSuchElementException
- Error的,则属于严重错误,如系统崩溃、虚拟机错误、动态链接失败等,这些错误无法恢复或者不可能捕捉,将导致应用程序中断,Error不需要捕获。
super出现在父类的子类中。有三种存在方式
- super.xxx(xxx为变量名或对象名)意思是获取父类中xxx的变量或引用
- super.xxx(); (xxx为方法名)意思是直接访问并调用父类中的方法
- super() 调用父类构造
注: super只能指代其直接父类
this() & super()在构造方法中的区别
- 调用super()必须写在子类构造方法的第一行, 否则编译不通过
- super从子类调用父类构造, this在同一类中调用其他构造均需要放在第一行
- 尽管可以用this调用一个构造器, 却不能调用2个
- this和super不能出现在同一个构造器中, 否则编译不通过
- this()、super()都指的对象,不可以在static环境中使用
- 本质this指向本对象的指针。super是一个关键字
构造内部类和静态内部类对象
public class Enclosingone {
public class Insideone {}
public static class Insideone{}
}
public class Test {
public static void main(String[] args) {
// 构造内部类对象需要外部类的引用
Enclosingone.Insideone obj1 = new Enclosingone().new Insideone();
// 构造静态内部类的对象
Enclosingone.Insideone obj2 = new Enclosingone.Insideone();
}
}
静态内部类不需要有指向外部类的引用。但非静态内部类需要持有对外部类的引用。非静态内部类能够访问外部类的静态和非静态成员。静态内部类不能访问外部类的非静态成员,只能访问外部类的静态成员。
序列化
声明为static和transient类型的数据不能被序列化, 反序列化需要一个无参构造函数
Java移位运算符
java中有三种移位运算符
<<:左移运算符,x << 1,相当于x乘以2(不溢出的情况下),低位补0>>:带符号右移,x >> 1,相当于x除以2,正数高位补0,负数高位补1>>>:无符号右移,忽略符号位,空位都以0补齐
形参&实参
形式参数可被视为local variable.形参和局部变量一样都不能离开方法。只有在方法中使用,不会在方法外可见。 形式参数只能用final修饰符,其它任何修饰符都会引起编译器错误。但是用这个修饰符也有一定的限制,就是在方法中不能对参数做任何修改。不过一般情况下,一个方法的形参不用final修饰。只有在特殊情况下,那就是: 方法内部类。一个方法内的内部类如果使用了这个方法的参数或者局部变量的话,这个参数或局部变量应该是final。 形参的值在调用时根据调用者更改,实参则用自身的值更改形参的值(指针、引用皆在此列),也就是说真正被传递的是实参。
局部变量为什么要初始化
局部变量是指类方法中的变量,必须初始化。局部变量运行时被分配在栈中,量大,生命周期短,如果虚拟机给每个局部变量都初始化一下,是一笔很大的开销,但变量不初始化为默认值就使用是不安全的。出于速度和安全性两个方面的综合考虑,解决方案就是虚拟机不初始化,但要求编写者一定要在使用前给变量赋值。
Java语言的鲁棒性
Java在编译和运行程序时,都要对可能出现的问题进行检查,以消除错误的产生。它提供自动垃圾收集来进行内存管理,防止程序员在管理内存时容易产生的错误。通过集成的面向对象的例外处理机制,在编译时,Java揭示出可能出现但未被处理的异常,帮助程序员正确地进行选择以防止系统的崩溃。另外,Java在编译时还可捕获类型声明中的许多常见错误,防止动态运行时不匹配问题的出现。
Java 基础 - 泛型机制详解
为什么会引入泛型
泛型的本质是为了参数化类型(在不创建新的类型的情况下,通过泛型指定的不同类型来控制形参具体限制的类型)。也就是说在泛型使用过程中,操作的数据类型被指定为一个参数,这种参数类型可以用在类、接口和方法中,分别被称为泛型类、泛型接口、泛型方法。
引入泛型的意义在于:
- 适用于多种数据类型执行相同的代码(代码复用)
我们通过一个例子来阐述,先看下下面的代码:
private static int add(int a, int b) {
System.out.println(a + "+" + b + "=" + (a + b));
return a + b;
}
private static float add(float a, float b) {
System.out.println(a + "+" + b + "=" + (a + b));
return a + b;
}
private static double add(double a, double b) {
System.out.println(a + "+" + b + "=" + (a + b));
return a + b;
}
如果没有泛型,要实现不同类型的加法,每种类型都需要重载一个add方法;通过泛型,我们可以复用为一个方法:
private static <T extends Number> double add(T a, T b) {
System.out.println(a + "+" + b + "=" + (a.doubleValue() + b.doubleValue()));
return a.doubleValue() + b.doubleValue();
}
- 泛型中的类型在使用时指定,不需要强制类型转换(类型安全,编译器会检查类型)
看下这个例子:
List list = new ArrayList();
list.add("xxString");
list.add(100d);
list.add(new Person());
我们在使用上述list中,list中的元素都是Object类型(无法约束其中的类型),所以在取出集合元素时需要人为的强制类型转化到具体的目标类型,且很容易出现java.lang.ClassCastException异常。
引入泛型,它将提供类型的约束,提供编译前的检查:
List<String> list = new ArrayList<String>();
// list中只能放String, 不能放其它类型的元素
泛型的基本使用
提示
我们通过一些例子来学习泛型的使用;泛型有三种使用方式,分别为:泛型类、泛型接口、泛型方法。一些例子可以参考《李兴华 - Java实战经典》。@pdai
泛型类
- 从一个简单的泛型类看起:
class Point<T>{ // 此处可以随便写标识符号,T是type的简称
private T var ; // var的类型由T指定,即:由外部指定
public T getVar(){ // 返回值的类型由外部决定
return var ;
}
public void setVar(T var){ // 设置的类型也由外部决定
this.var = var ;
}
}
public class GenericsDemo06{
public static void main(String args[]){
Point<String> p = new Point<String>() ; // 里面的var类型为String类型
p.setVar("it") ; // 设置字符串
System.out.println(p.getVar().length()) ; // 取得字符串的长度
}
}
- 多元泛型
class Notepad<K,V>{ // 此处指定了两个泛型类型
private K key ; // 此变量的类型由外部决定
private V value ; // 此变量的类型由外部决定
public K getKey(){
return this.key ;
}
public V getValue(){
return this.value ;
}
public void setKey(K key){
this.key = key ;
}
public void setValue(V value){
this.value = value ;
}
}
public class GenericsDemo09{
public static void main(String args[]){
Notepad<String,Integer> t = null ; // 定义两个泛型类型的对象
t = new Notepad<String,Integer>() ; // 里面的key为String,value为Integer
t.setKey("汤姆") ; // 设置第一个内容
t.setValue(20) ; // 设置第二个内容
System.out.print("姓名;" + t.getKey()) ; // 取得信息
System.out.print(",年龄;" + t.getValue()) ; // 取得信息
}
}
泛型接口
- 简单的泛型接口
interface Info<T>{ // 在接口上定义泛型
public T getVar() ; // 定义抽象方法,抽象方法的返回值就是泛型类型
}
class InfoImpl<T> implements Info<T>{ // 定义泛型接口的子类
private T var ; // 定义属性
public InfoImpl(T var){ // 通过构造方法设置属性内容
this.setVar(var) ;
}
public void setVar(T var){
this.var = var ;
}
public T getVar(){
return this.var ;
}
}
public class GenericsDemo24{
public static void main(String arsg[]){
Info<String> i = null; // 声明接口对象
i = new InfoImpl<String>("汤姆") ; // 通过子类实例化对象
System.out.println("内容:" + i.getVar()) ;
}
}
泛型方法
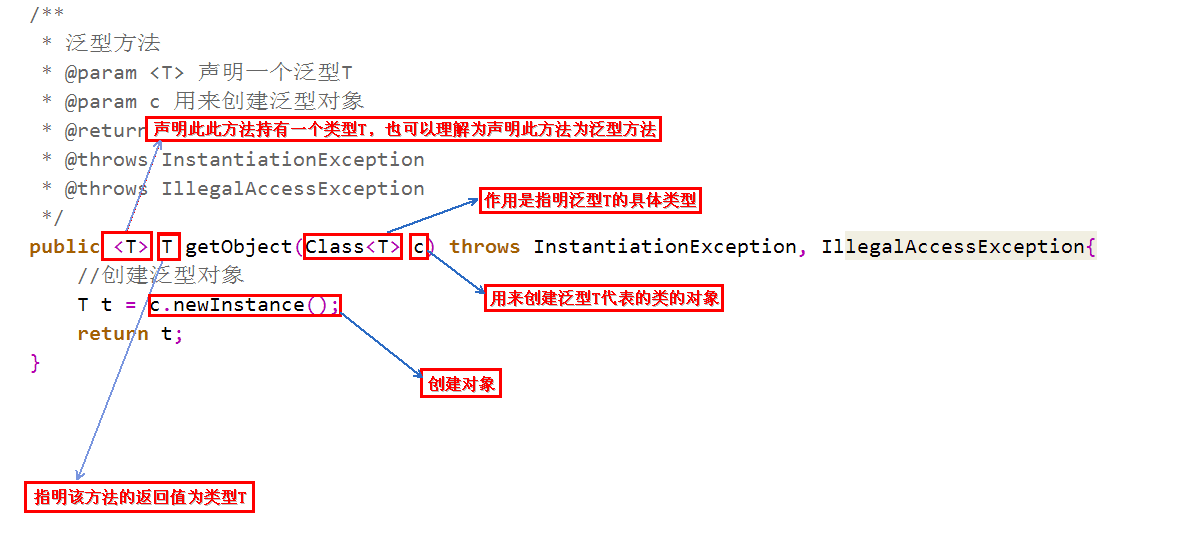
泛型方法,是在调用方法的时候指明泛型的具体类型。重点看下泛型的方法(图参考自:https://www.cnblogs.com/iyangyuan/archive/2013/04/09/3011274.html)
-
定义泛型方法语法格式
-
调用泛型方法语法格式

说明一下,定义泛型方法时,必须在返回值前边加一个<T>,来声明这是一个泛型方法,持有一个泛型T,然后才可以用泛型T作为方法的返回值。
Class<T>的作用就是指明泛型的具体类型,而Class<T>类型的变量c,可以用来创建泛型类的对象。
为什么要用变量c来创建对象呢?既然是泛型方法,就代表着我们不知道具体的类型是什么,也不知道构造方法如何,因此没有办法去new一个对象,但可以利用变量c的newInstance方法去创建对象,也就是利用反射创建对象。
泛型方法要求的参数是Class<T>类型,而Class.forName()方法的返回值也是Class<T>,因此可以用Class.forName()作为参数。其中,forName()方法中的参数是何种类型,返回的Class<T>就是何种类型。在本例中,forName()方法中传入的是User类的完整路径,因此返回的是Class<User>类型的对象,因此调用泛型方法时,变量c的类型就是Class<User>,因此泛型方法中的泛型T就被指明为User,因此变量obj的类型为User。
当然,泛型方法不是仅仅可以有一个参数Class<T>,可以根据需要添加其他参数。
为什么要使用泛型方法呢?因为泛型类要在实例化的时候就指明类型,如果想换一种类型,不得不重新new一次,可能不够灵活;而泛型方法可以在调用的时候指明类型,更加灵活。
泛型的上下限
- 先看下如下的代码,很明显是会报错的 (具体错误原因请参考后文)。
class A{}
class B extends A {}
// 如下两个方法不会报错
public static void funA(A a) {
// ...
}
public static void funB(B b) {
funA(b);
// ...
}
// 如下funD方法会报错
public static void funC(List<A> listA) {
// ...
}
public static void funD(List<B> listB) {
funC(listB); // Unresolved compilation problem: The method doPrint(List<A>) in the type test is not applicable for the arguments (List<B>)
// ...
}
那么如何解决呢?
为了解决泛型中隐含的转换问题,Java泛型加入了类型参数的上下边界机制。<? extends A>表示该类型参数可以是A(上边界)或者A的子类类型。编译时擦除到类型A,即用A类型代替类型参数。这种方法可以解决开始遇到的问题,编译器知道类型参数的范围,如果传入的实例类型B是在这个范围内的话允许转换,这时只要一次类型转换就可以了,运行时会把对象当做A的实例看待。
public static void funC(List<? extends A> listA) {
// ...
}
public static void funD(List<B> listB) {
funC(listB); // OK
// ...
}
- 泛型上下限的引入
在使用泛型的时候,我们可以为传入的泛型类型实参进行上下边界的限制,如:类型实参只准传入某种类型的父类或某种类型的子类。
上限
class Info<T extends Number>{ // 此处泛型只能是数字类型
private T var ; // 定义泛型变量
public void setVar(T var){
this.var = var ;
}
public T getVar(){
return this.var ;
}
public String toString(){ // 直接打印
return this.var.toString() ;
}
}
public class demo1{
public static void main(String args[]){
Info<Integer> i1 = new Info<Integer>() ; // 声明Integer的泛型对象
}
}
下限
class Info<T>{
private T var ; // 定义泛型变量
public void setVar(T var){
this.var = var ;
}
public T getVar(){
return this.var ;
}
public String toString(){ // 直接打印
return this.var.toString() ;
}
}
public class GenericsDemo21{
public static void main(String args[]){
Info<String> i1 = new Info<String>() ; // 声明String的泛型对象
Info<Object> i2 = new Info<Object>() ; // 声明Object的泛型对象
i1.setVar("hello") ;
i2.setVar(new Object()) ;
fun(i1) ;
fun(i2) ;
}
public static void fun(Info<? super String> temp){ // 只能接收String或Object类型的泛型,String类的父类只有Object类
System.out.print(temp + ", ") ;
}
}
小结
<?> 无限制通配符
<? extends E> extends 关键字声明了类型的上界,表示参数化的类型可能是所指定的类型,或者是此类型的子类
<? super E> super 关键字声明了类型的下界,表示参数化的类型可能是指定的类型,或者是此类型的父类
// 使用原则《Effictive Java》
// 为了获得最大限度的灵活性,要在表示 生产者或者消费者 的输入参数上使用通配符,使用的规则就是:生产者有上限、消费者有下限
1. 如果参数化类型表示一个 T 的生产者,使用 < ? extends T>;
2. 如果它表示一个 T 的消费者,就使用 < ? super T>;
3. 如果既是生产又是消费,那使用通配符就没什么意义了,因为你需要的是精确的参数类型。
- 再看一个实际例子,加深印象
private <E extends Comparable<? super E>> E max(List<? extends E> e1) {
if (e1 == null){
return null;
}
//迭代器返回的元素属于 E 的某个子类型
Iterator<? extends E> iterator = e1.iterator();
E result = iterator.next();
while (iterator.hasNext()){
E next = iterator.next();
if (next.compareTo(result) > 0){
result = next;
}
}
return result;
}
上述代码中的类型参数 E 的范围是<E extends Comparable<? super E>>,我们可以分步查看:
- 要进行比较,所以 E 需要是可比较的类,因此需要
extends Comparable<…>(注意这里不要和继承的extends搞混了,不一样) Comparable< ? super E>要对 E 进行比较,即 E 的消费者,所以需要用 super- 而参数
List< ? extends E>表示要操作的数据是 E 的子类的列表,指定上限,这样容器才够大 - 多个限制
使用&符号
public class Client {
//工资低于2500元的上斑族并且站立的乘客车票打8折
public static <T extends Staff & Passenger> void discount(T t){
if(t.getSalary()<2500 && t.isStanding()){
System.out.println("恭喜你!您的车票打八折!");
}
}
public static void main(String[] args) {
discount(new Me());
}
}
泛型数组
具体可以参考下文中关于泛型数组的理解。
首先,我们泛型数组相关的申明:
List<String>[] list11 = new ArrayList<String>[10]; //编译错误,非法创建
List<String>[] list12 = new ArrayList<?>[10]; //编译错误,需要强转类型
List<String>[] list13 = (List<String>[]) new ArrayList<?>[10]; //OK,但是会有警告
List<?>[] list14 = new ArrayList<String>[10]; //编译错误,非法创建
List<?>[] list15 = new ArrayList<?>[10]; //OK
List<String>[] list6 = new ArrayList[10]; //OK,但是会有警告
那么通常我们如何用呢?
- 讨巧的使用场景
public class GenericsDemo30{
public static void main(String args[]){
Integer i[] = fun1(1,2,3,4,5,6) ; // 返回泛型数组
fun2(i) ;
}
public static <T> T[] fun1(T...arg){ // 接收可变参数
return arg ; // 返回泛型数组
}
public static <T> void fun2(T param[]){ // 输出
System.out.print("接收泛型数组:") ;
for(T t:param){
System.out.print(t + "、") ;
}
}
}
- 合理使用
public ArrayWithTypeToken(Class<T> type, int size) {
array = (T[]) Array.newInstance(type, size);
}
具体可以查看后文解释。
深入理解泛型
提示
我们通过泛型背后的类型擦除以及相关的问题来进一步理解泛型。@pdai
如何理解Java中的泛型是伪泛型?泛型中类型擦除
Java泛型这个特性是从JDK 1.5才开始加入的,因此为了兼容之前的版本,Java泛型的实现采取了“伪泛型”的策略,即Java在语法上支持泛型,但是在编译阶段会进行所谓的“类型擦除”(Type Erasure),将所有的泛型表示(尖括号中的内容)都替换为具体的类型(其对应的原生态类型),就像完全没有泛型一样。理解类型擦除对于用好泛型是很有帮助的,尤其是一些看起来“疑难杂症”的问题,弄明白了类型擦除也就迎刃而解了。
泛型的类型擦除原则是:
- 消除类型参数声明,即删除
<>及其包围的部分。 - 根据类型参数的上下界推断并替换所有的类型参数为原生态类型:如果类型参数是无限制通配符或没有上下界限定则替换为Object,如果存在上下界限定则根据子类替换原则取类型参数的最左边限定类型(即父类)。
- 为了保证类型安全,必要时插入强制类型转换代码。
- 自动产生“桥接方法”以保证擦除类型后的代码仍然具有泛型的“多态性”。
那么如何进行擦除的呢?
参考自:http://softlab.sdut.edu.cn/blog/subaochen/2017/01/generics-type-erasure/
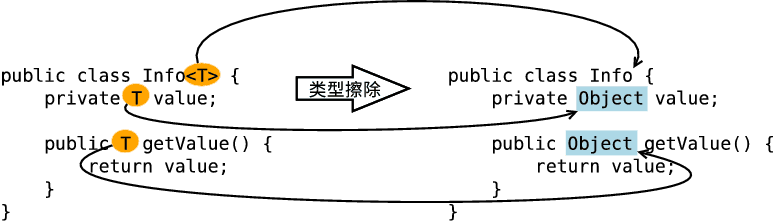
- 擦除类定义中的类型参数 - 无限制类型擦除
当类定义中的类型参数没有任何限制时,在类型擦除中直接被替换为Object,即形如<T>和<?>的类型参数都被替换为Object。
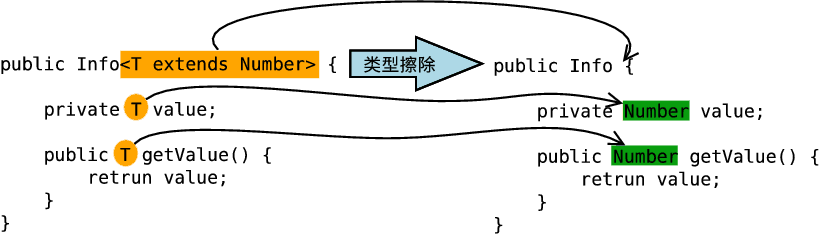
- 擦除类定义中的类型参数 - 有限制类型擦除
当类定义中的类型参数存在限制(上下界)时,在类型擦除中替换为类型参数的上界或者下界,比如形如<T extends Number>和<? extends Number>的类型参数被替换为Number,<? super Number>被替换为Object。
- 擦除方法定义中的类型参数
擦除方法定义中的类型参数原则和擦除类定义中的类型参数是一样的,这里仅以擦除方法定义中的有限制类型参数为例。

如何证明类型的擦除呢?
我们通过两个例子证明Java类型的类型擦除
- 原始类型相等
public class Test {
public static void main(String[] args) {
ArrayList<String> list1 = new ArrayList<String>();
list1.add("abc");
ArrayList<Integer> list2 = new ArrayList<Integer>();
list2.add(123);
System.out.println(list1.getClass() == list2.getClass()); // true
}
}
在这个例子中,我们定义了两个ArrayList数组,不过一个是ArrayList<String>泛型类型的,只能存储字符串;一个是ArrayList<Integer>泛型类型的,只能存储整数,最后,我们通过list1对象和list2对象的getClass()方法获取他们的类的信息,最后发现结果为true。说明泛型类型String和Integer都被擦除掉了,只剩下原始类型。
- 通过反射添加其它类型元素
public class Test {
public static void main(String[] args) throws Exception {
ArrayList<Integer> list = new ArrayList<Integer>();
list.add(1); //这样调用 add 方法只能存储整形,因为泛型类型的实例为 Integer
list.getClass().getMethod("add", Object.class).invoke(list, "asd");
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
}
}
在程序中定义了一个ArrayList泛型类型实例化为Integer对象,如果直接调用add()方法,那么只能存储整数数据,不过当我们利用反射调用add()方法的时候,却可以存储字符串,这说明了Integer泛型实例在编译之后被擦除掉了,只保留了原始类型。
如何理解类型擦除后保留的原始类型?
在上面,两次提到了原始类型,什么是原始类型?
原始类型 就是擦除去了泛型信息,最后在字节码中的类型变量的真正类型,无论何时定义一个泛型,相应的原始类型都会被自动提供,类型变量擦除,并使用其限定类型(无限定的变量用Object)替换。
- 原始类型Object
class Pair<T> {
private T value;
public T getValue() {
return value;
}
public void setValue(T value) {
this.value = value;
}
}
Pair的原始类型为:
class Pair {
private Object value;
public Object getValue() {
return value;
}
public void setValue(Object value) {
this.value = value;
}
}
因为在Pair<T>中,T 是一个无限定的类型变量,所以用Object替换,其结果就是一个普通的类,如同泛型加入Java语言之前的已经实现的样子。在程序中可以包含不同类型的Pair,如Pair<String>或Pair<Integer>,但是擦除类型后他们的就成为原始的Pair类型了,原始类型都是Object。
从上面章节,我们也可以明白ArrayList被擦除类型后,原始类型也变为Object,所以通过反射我们就可以存储字符串了。
如果类型变量有限定,那么原始类型就用第一个边界的类型变量类替换。
比如: Pair这样声明的话
public class Pair<T extends Comparable> {}
那么原始类型就是Comparable。
要区分原始类型和泛型变量的类型。
在调用泛型方法时,可以指定泛型,也可以不指定泛型:
- 在不指定泛型的情况下,泛型变量的类型为该方法中的几种类型的同一父类的最小级,直到Object
- 在指定泛型的情况下,该方法的几种类型必须是该泛型的实例的类型或者其子类
public class Test {
public static void main(String[] args) {
/**不指定泛型的时候*/
int i = Test.add(1, 2); //这两个参数都是Integer,所以T为Integer类型
Number f = Test.add(1, 1.2); //这两个参数一个是Integer,一个是Float,所以取同一父类的最小级,为Number
Object o = Test.add(1, "asd"); //这两个参数一个是Integer,一个是String,所以取同一父类的最小级,为Object
/**指定泛型的时候*/
int a = Test.<Integer>add(1, 2); //指定了Integer,所以只能为Integer类型或者其子类
int b = Test.<Integer>add(1, 2.2); //编译错误,指定了Integer,不能为Float
Number c = Test.<Number>add(1, 2.2); //指定为Number,所以可以为Integer和Float
}
//这是一个简单的泛型方法
public static <T> T add(T x,T y){
return y;
}
}
其实在泛型类中,不指定泛型的时候,也差不多,只不过这个时候的泛型为Object,就比如ArrayList中,如果不指定泛型,那么这个ArrayList可以存储任意的对象。
- Object泛型
public static void main(String[] args) {
ArrayList list = new ArrayList();
list.add(1);
list.add("121");
list.add(new Date());
}
如何理解泛型的编译期检查?
既然说类型变量会在编译的时候擦除掉,那为什么我们往 ArrayList 创建的对象中添加整数会报错呢?不是说泛型变量String会在编译的时候变为Object类型吗?为什么不能存别的类型呢?既然类型擦除了,如何保证我们只能使用泛型变量限定的类型呢?
Java编译器是通过先检查代码中泛型的类型,然后在进行类型擦除,再进行编译。
例如:
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<String>();
list.add("123");
list.add(123);//编译错误
}
在上面的程序中,使用add方法添加一个整型,在IDE中,直接会报错,说明这就是在编译之前的检查,因为如果是在编译之后检查,类型擦除后,原始类型为Object,是应该允许任意引用类型添加的。可实际上却不是这样的,这恰恰说明了关于泛型变量的使用,是会在编译之前检查的。
那么,这个类型检查是针对谁的呢?我们先看看参数化类型和原始类型的兼容。
以 ArrayList举例子,以前的写法:
ArrayList list = new ArrayList();
现在的写法:
ArrayList<String> list = new ArrayList<String>();
如果是与以前的代码兼容,各种引用传值之间,必然会出现如下的情况:
ArrayList<String> list1 = new ArrayList(); //第一种 情况
ArrayList list2 = new ArrayList<String>(); //第二种 情况
这样是没有错误的,不过会有个编译时警告。
不过在第一种情况,可以实现与完全使用泛型参数一样的效果,第二种则没有效果。
因为类型检查就是编译时完成的,new ArrayList()只是在内存中开辟了一个存储空间,可以存储任何类型对象,而真正涉及类型检查的是它的引用,因为我们是使用它引用list1来调用它的方法,比如说调用add方法,所以list1引用能完成泛型类型的检查。而引用list2没有使用泛型,所以不行。
举例子:
public class Test {
public static void main(String[] args) {
ArrayList<String> list1 = new ArrayList();
list1.add("1"); //编译通过
list1.add(1); //编译错误
String str1 = list1.get(0); //返回类型就是String
ArrayList list2 = new ArrayList<String>();
list2.add("1"); //编译通过
list2.add(1); //编译通过
Object object = list2.get(0); //返回类型就是Object
new ArrayList<String>().add("11"); //编译通过
new ArrayList<String>().add(22); //编译错误
String str2 = new ArrayList<String>().get(0); //返回类型就是String
}
}
通过上面的例子,我们可以明白,类型检查就是针对引用的,谁是一个引用,用这个引用调用泛型方法,就会对这个引用调用的方法进行类型检测,而无关它真正引用的对象。
泛型中参数话类型为什么不考虑继承关系?
在Java中,像下面形式的引用传递是不允许的:
ArrayList<String> list1 = new ArrayList<Object>(); //编译错误
ArrayList<Object> list2 = new ArrayList<String>(); //编译错误
- 我们先看第一种情况,将第一种情况拓展成下面的形式:
ArrayList<Object> list1 = new ArrayList<Object>();
list1.add(new Object());
list1.add(new Object());
ArrayList<String> list2 = list1; //编译错误
实际上,在第4行代码的时候,就会有编译错误。那么,我们先假设它编译没错。那么当我们使用list2引用用get()方法取值的时候,返回的都是String类型的对象(上面提到了,类型检测是根据引用来决定的),可是它里面实际上已经被我们存放了Object类型的对象,这样就会有ClassCastException了。所以为了避免这种极易出现的错误,Java不允许进行这样的引用传递。(这也是泛型出现的原因,就是为了解决类型转换的问题,我们不能违背它的初衷)。
- 再看第二种情况,将第二种情况拓展成下面的形式:
ArrayList<String> list1 = new ArrayList<String>();
list1.add(new String());
list1.add(new String());
ArrayList<Object> list2 = list1; //编译错误
没错,这样的情况比第一种情况好的多,最起码,在我们用list2取值的时候不会出现ClassCastException,因为是从String转换为Object。可是,这样做有什么意义呢,泛型出现的原因,就是为了解决类型转换的问题。
我们使用了泛型,到头来,还是要自己强转,违背了泛型设计的初衷。所以java不允许这么干。再说,你如果又用list2往里面add()新的对象,那么到时候取得时候,我怎么知道我取出来的到底是String类型的,还是Object类型的呢?
所以,要格外注意,泛型中的引用传递的问题。
如何理解泛型的多态?泛型的桥接方法
类型擦除会造成多态的冲突,而JVM解决方法就是桥接方法。
现在有这样一个泛型类:
class Pair<T> {
private T value;
public T getValue() {
return value;
}
public void setValue(T value) {
this.value = value;
}
}
然后我们想要一个子类继承它。
class DateInter extends Pair<Date> {
@Override
public void setValue(Date value) {
super.setValue(value);
}
@Override
public Date getValue() {
return super.getValue();
}
}
在这个子类中,我们设定父类的泛型类型为Pair<Date>,在子类中,我们覆盖了父类的两个方法,我们的原意是这样的:将父类的泛型类型限定为Date,那么父类里面的两个方法的参数都为Date类型。
public Date getValue() {
return value;
}
public void setValue(Date value) {
this.value = value;
}
所以,我们在子类中重写这两个方法一点问题也没有,实际上,从他们的@Override标签中也可以看到,一点问题也没有,实际上是这样的吗?
分析:实际上,类型擦除后,父类的的泛型类型全部变为了原始类型Object,所以父类编译之后会变成下面的样子:
class Pair {
private Object value;
public Object getValue() {
return value;
}
public void setValue(Object value) {
this.value = value;
}
}
再看子类的两个重写的方法的类型:
@Override
public void setValue(Date value) {
super.setValue(value);
}
@Override
public Date getValue() {
return super.getValue();
}
先来分析setValue方法,父类的类型是Object,而子类的类型是Date,参数类型不一样,这如果实在普通的继承关系中,根本就不会是重写,而是重载。 我们在一个main方法测试一下:
public static void main(String[] args) throws ClassNotFoundException {
DateInter dateInter = new DateInter();
dateInter.setValue(new Date());
dateInter.setValue(new Object()); //编译错误
}
如果是重载,那么子类中两个setValue方法,一个是参数Object类型,一个是Date类型,可是我们发现,根本就没有这样的一个子类继承自父类的Object类型参数的方法。所以说,却是是重写了,而不是重载了。
为什么会这样呢?
原因是这样的,我们传入父类的泛型类型是Date,Pair<Date>,我们的本意是将泛型类变为如下:
class Pair {
private Date value;
public Date getValue() {
return value;
}
public void setValue(Date value) {
this.value = value;
}
}
然后再子类中重写参数类型为Date的那两个方法,实现继承中的多态。
可是由于种种原因,虚拟机并不能将泛型类型变为Date,只能将类型擦除掉,变为原始类型Object。这样,我们的本意是进行重写,实现多态。可是类型擦除后,只能变为了重载。这样,类型擦除就和多态有了冲突。JVM知道你的本意吗?知道!!!可是它能直接实现吗,不能!!!如果真的不能的话,那我们怎么去重写我们想要的Date类型参数的方法啊。
于是JVM采用了一个特殊的方法,来完成这项功能,那就是桥方法。
首先,我们用javap -c className的方式反编译下DateInter子类的字节码,结果如下:
class com.tao.test.DateInter extends com.tao.test.Pair<java.util.Date> {
com.tao.test.DateInter();
Code:
0: aload_0
1: invokespecial #8 // Method com/tao/test/Pair."<init>":()V
4: return
public void setValue(java.util.Date); //我们重写的setValue方法
Code:
0: aload_0
1: aload_1
2: invokespecial #16 // Method com/tao/test/Pair.setValue:(Ljava/lang/Object;)V
5: return
public java.util.Date getValue(); //我们重写的getValue方法
Code:
0: aload_0
1: invokespecial #23 // Method com/tao/test/Pair.getValue:()Ljava/lang/Object;
4: checkcast #26 // class java/util/Date
7: areturn
public java.lang.Object getValue(); //编译时由编译器生成的桥方法
Code:
0: aload_0
1: invokevirtual #28 // Method getValue:()Ljava/util/Date 去调用我们重写的getValue方法;
4: areturn
public void setValue(java.lang.Object); //编译时由编译器生成的桥方法
Code:
0: aload_0
1: aload_1
2: checkcast #26 // class java/util/Date
5: invokevirtual #30 // Method setValue:(Ljava/util/Date; 去调用我们重写的setValue方法)V
8: return
}
从编译的结果来看,我们本意重写setValue和getValue方法的子类,竟然有4个方法,其实不用惊奇,最后的两个方法,就是编译器自己生成的桥方法。可以看到桥方法的参数类型都是Object,也就是说,子类中真正覆盖父类两个方法的就是这两个我们看不到的桥方法。而打在我们自己定义的setvalue和getValue方法上面的@Oveerride只不过是假象。而桥方法的内部实现,就只是去调用我们自己重写的那两个方法。
所以,虚拟机巧妙的使用了桥方法,来解决了类型擦除和多态的冲突。
不过,要提到一点,这里面的setValue和getValue这两个桥方法的意义又有不同。
setValue方法是为了解决类型擦除与多态之间的冲突。
而getValue却有普遍的意义,怎么说呢,如果这是一个普通的继承关系:
那么父类的getValue方法如下:
public Object getValue() {
return super.getValue();
}
而子类重写的方法是:
public Date getValue() {
return super.getValue();
}
其实这在普通的类继承中也是普遍存在的重写,这就是协变。
并且,还有一点也许会有疑问,子类中的桥方法Object getValue()和Date getValue()是同时存在的,可是如果是常规的两个方法,他们的方法签名是一样的,也就是说虚拟机根本不能分别这两个方法。如果是我们自己编写Java代码,这样的代码是无法通过编译器的检查的,但是虚拟机却是允许这样做的,因为虚拟机通过参数类型和返回类型来确定一个方法,所以编译器为了实现泛型的多态允许自己做这个看起来“不合法”的事情,然后交给虚拟器去区别。
如何理解基本类型不能作为泛型类型?
比如,我们没有
ArrayList<int>,只有ArrayList<Integer>, 为何?
因为当类型擦除后,ArrayList的原始类型变为Object,但是Object类型不能存储int值,只能引用Integer的值。
另外需要注意,我们能够使用list.add(1)是因为Java基础类型的自动装箱拆箱操作。
如何理解泛型类型不能实例化?
不能实例化泛型类型, 这本质上是由于类型擦除决定的:
我们可以看到如下代码会在编译器中报错:
T test = new T(); // ERROR
因为在 Java 编译期没法确定泛型参数化类型,也就找不到对应的类字节码文件,所以自然就不行了,此外由于T 被擦除为 Object,如果可以 new T() 则就变成了 new Object(),失去了本意。 如果我们确实需要实例化一个泛型,应该如何做呢?可以通过反射实现:
static <T> T newTclass (Class < T > clazz) throws InstantiationException, IllegalAccessException {
T obj = clazz.newInstance();
return obj;
}
泛型数组:能不能采用具体的泛型类型进行初始化?
我们先来看下Oracle官网提供的一个例子:
List<String>[] lsa = new List<String>[10]; // Not really allowed.
Object o = lsa;
Object[] oa = (Object[]) o;
List<Integer> li = new ArrayList<Integer>();
li.add(new Integer(3));
oa[1] = li; // Unsound, but passes run time store check
String s = lsa[1].get(0); // Run-time error ClassCastException.
由于 JVM 泛型的擦除机制,所以上面代码可以给 oa[1] 赋值为 ArrayList 也不会出现异常,但是在取出数据的时候却要做一次类型转换,所以就会出现 ClassCastException,如果可以进行泛型数组的声明则上面说的这种情况在编译期不会出现任何警告和错误,只有在运行时才会出错,但是泛型的出现就是为了消灭 ClassCastException,所以如果 Java 支持泛型数组初始化操作就是搬起石头砸自己的脚。
而对于下面的代码来说是成立的:
List<?>[] lsa = new List<?>[10]; // OK, array of unbounded wildcard type.
Object o = lsa;
Object[] oa = (Object[]) o;
List<Integer> li = new ArrayList<Integer>();
li.add(new Integer(3));
oa[1] = li; // Correct.
Integer i = (Integer) lsa[1].get(0); // OK
所以说采用通配符的方式初始化泛型数组是允许的,因为对于通配符的方式最后取出数据是要做显式类型转换的,符合预期逻辑。综述就是说Java 的泛型数组初始化时数组类型不能是具体的泛型类型,只能是通配符的形式,因为具体类型会导致可存入任意类型对象,在取出时会发生类型转换异常,会与泛型的设计思想冲突,而通配符形式本来就需要自己强转,符合预期。
Oracle 官方文档:https://docs.oracle.com/javase/tutorial/extra/generics/fineprint.html在新窗口打开
更进一步的,我们看看如下的代码:
List<String>[] list11 = new ArrayList<String>[10]; //编译错误,非法创建
List<String>[] list12 = new ArrayList<?>[10]; //编译错误,需要强转类型
List<String>[] list13 = (List<String>[]) new ArrayList<?>[10]; //OK,但是会有警告
List<?>[] list14 = new ArrayList<String>[10]; //编译错误,非法创建
List<?>[] list15 = new ArrayList<?>[10]; //OK
List<String>[] list6 = new ArrayList[10]; //OK,但是会有警告
因为在 Java 中是不能创建一个确切的泛型类型的数组的,除非是采用通配符的方式且要做显式类型转换才可以。
泛型数组:如何正确的初始化泛型数组实例?
这个无论我们通过
new ArrayList[10]的形式还是通过泛型通配符的形式初始化泛型数组实例都是存在警告的,也就是说仅仅语法合格,运行时潜在的风险需要我们自己来承担,因此那些方式初始化泛型数组都不是最优雅的方式。
我们在使用到泛型数组的场景下应该尽量使用列表集合替换,此外也可以通过使用 java.lang.reflect.Array.newInstance(Class<T> componentType, int length) 方法来创建一个具有指定类型和维度的数组,如下:
public class ArrayWithTypeToken<T> {
private T[] array;
public ArrayWithTypeToken(Class<T> type, int size) {
array = (T[]) Array.newInstance(type, size);
}
public void put(int index, T item) {
array[index] = item;
}
public T get(int index) {
return array[index];
}
public T[] create() {
return array;
}
}
//...
ArrayWithTypeToken<Integer> arrayToken = new ArrayWithTypeToken<Integer>(Integer.class, 100);
Integer[] array = arrayToken.create();
所以使用反射来初始化泛型数组算是优雅实现,因为泛型类型 T在运行时才能被确定下来,我们能创建泛型数组也必然是在 Java 运行时想办法,而运行时能起作用的技术最好的就是反射了。
如何理解泛型类中的静态方法和静态变量?
泛型类中的静态方法和静态变量不可以使用泛型类所声明的泛型类型参数
举例说明:
public class Test2<T> {
public static T one; //编译错误
public static T show(T one){ //编译错误
return null;
}
}
因为泛型类中的泛型参数的实例化是在定义对象的时候指定的,而静态变量和静态方法不需要使用对象来调用。对象都没有创建,如何确定这个泛型参数是何种类型,所以当然是错误的。
但是要注意区分下面的一种情况:
public class Test2<T> {
public static <T >T show(T one){ //这是正确的
return null;
}
}
因为这是一个泛型方法,在泛型方法中使用的T是自己在方法中定义的 T,而不是泛型类中的T。
如何理解异常中使用泛型?
- 不能抛出也不能捕获泛型类的对象。事实上,泛型类扩展Throwable都不合法。例如:下面的定义将不会通过编译:
public class Problem<T> extends Exception {
}
为什么不能扩展Throwable,因为异常都是在运行时捕获和抛出的,而在编译的时候,泛型信息全都会被擦除掉,那么,假设上面的编译可行,那么,在看下面的定义:
try{
} catch(Problem<Integer> e1) {
} catch(Problem<Number> e2) {
}
类型信息被擦除后,那么两个地方的catch都变为原始类型Object,那么也就是说,这两个地方的catch变的一模一样,就相当于下面的这样
try{
} catch(Problem<Object> e1) {
} catch(Problem<Object> e2) {
}
这个当然就是不行的。
- 不能再catch子句中使用泛型变量
public static <T extends Throwable> void doWork(Class<T> t) {
try {
...
} catch(T e) { //编译错误
...
}
}
因为泛型信息在编译的时候已经变为原始类型,也就是说上面的T会变为原始类型Throwable,那么如果可以再catch子句中使用泛型变量,那么,下面的定义呢:
public static <T extends Throwable> void doWork(Class<T> t){
try {
} catch(T e) { //编译错误
} catch(IndexOutOfBounds e) {
}
}
根据异常捕获的原则,一定是子类在前面,父类在后面,那么上面就违背了这个原则。即使你在使用该静态方法的使用T是ArrayIndexOutofBounds,在编译之后还是会变成Throwable,ArrayIndexOutofBounds是IndexOutofBounds的子类,违背了异常捕获的原则。所以java为了避免这样的情况,禁止在catch子句中使用泛型变量。
- 但是在异常声明中可以使用类型变量。下面方法是合法的。
public static<T extends Throwable> void doWork(T t) throws T {
try{
...
} catch(Throwable realCause) {
t.initCause(realCause);
throw t;
}
}
上面的这样使用是没问题的。
如何获取泛型的参数类型?
既然类型被擦除了,那么如何获取泛型的参数类型呢?可以通过反射(
java.lang.reflect.Type)获取泛型
java.lang.reflect.Type是Java中所有类型的公共高级接口, 代表了Java中的所有类型. Type体系中类型的包括:数组类型(GenericArrayType)、参数化类型(ParameterizedType)、类型变量(TypeVariable)、通配符类型(WildcardType)、原始类型(Class)、基本类型(Class), 以上这些类型都实现Type接口。
public class GenericType<T> {
private T data;
public T getData() {
return data;
}
public void setData(T data) {
this.data = data;
}
public static void main(String[] args) {
GenericType<String> genericType = new GenericType<String>() {};
Type superclass = genericType.getClass().getGenericSuperclass();
//getActualTypeArguments 返回确切的泛型参数, 如Map<String, Integer>返回[String, Integer]
Type type = ((ParameterizedType) superclass).getActualTypeArguments()[0];
System.out.println(type);//class java.lang.String
}
}
其中 ParameterizedType:
public interface ParameterizedType extends Type {
// 返回确切的泛型参数, 如Map<String, Integer>返回[String, Integer]
Type[] getActualTypeArguments();
//返回当前class或interface声明的类型, 如List<?>返回List
Type getRawType();
//返回所属类型. 如,当前类型为O<T>.I<S>, 则返回O<T>. 顶级类型将返回null
Type getOwnerType();
}
注解机制详解
注解基础
注解是JDK1.5版本开始引入的一个特性,用于对代码进行说明,可以对包、类、接口、字段、方法参数、局部变量等进行注解。它主要的作用有以下四方面:
- 生成文档,通过代码里标识的元数据生成javadoc文档。
- 编译检查,通过代码里标识的元数据让编译器在编译期间进行检查验证。
- 编译时动态处理,编译时通过代码里标识的元数据动态处理,例如动态生成代码。
- 运行时动态处理,运行时通过代码里标识的元数据动态处理,例如使用反射注入实例。
这么来说是比较抽象的,我们具体看下注解的常见分类:
- Java自带的标准注解,包括
@Override、@Deprecated和@SuppressWarnings,分别用于标明重写某个方法、标明某个类或方法过时、标明要忽略的警告,用这些注解标明后编译器就会进行检查。 - 元注解,元注解是用于定义注解的注解,包括
@Retention、@Target、@Inherited、@Documented,@Retention用于标明注解被保留的阶段,@Target用于标明注解使用的范围,@Inherited用于标明注解可继承,@Documented用于标明是否生成javadoc文档。 - 自定义注解,可以根据自己的需求定义注解,并可用元注解对自定义注解进行注解。
接下来我们通过这个分类角度来理解注解。
Java内置注解
我们从最为常见的Java内置的注解开始说起,先看下下面的代码:
class A{
public void test() {
}
}
class B extends A{
/**
* 重载父类的test方法
*/
@Override
public void test() {
}
/**
* 被弃用的方法
*/
@Deprecated
public void oldMethod() {
}
/**
* 忽略告警
*
* @return
*/
@SuppressWarnings("rawtypes")
public List processList() {
List list = new ArrayList();
return list;
}
}
Java 1.5开始自带的标准注解,包括@Override、@Deprecated和@SuppressWarnings:
@Override:表示当前的方法定义将覆盖父类中的方法@Deprecated:表示代码被弃用,如果使用了被@Deprecated注解的代码则编译器将发出警告@SuppressWarnings:表示关闭编译器警告信息
我们再具体看下这几个内置注解,同时通过这几个内置注解中的元注解的定义来引出元注解。
内置注解 - @Override
我们先来看一下这个注解类型的定义:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.SOURCE)
public @interface Override {
}
从它的定义我们可以看到,这个注解可以被用来修饰方法,并且它只在编译时有效,在编译后的class文件中便不再存在。这个注解的作用我们大家都不陌生,那就是告诉编译器被修饰的方法是重写的父类的中的相同签名的方法,编译器会对此做出检查,若发现父类中不存在这个方法或是存在的方法签名不同,则会报错。
内置注解 - @Deprecated
这个注解的定义如下:
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(value={CONSTRUCTOR, FIELD, LOCAL_VARIABLE, METHOD, PACKAGE, PARAMETER, TYPE})
public @interface Deprecated {
}
从它的定义我们可以知道,它会被文档化,能够保留到运行时,能够修饰构造方法、属性、局部变量、方法、包、参数、类型。这个注解的作用是告诉编译器被修饰的程序元素已被“废弃”,不再建议用户使用。
内置注解 - @SuppressWarnings
这个注解我们也比较常用到,先来看下它的定义:
@Target({TYPE, FIELD, METHOD, PARAMETER, CONSTRUCTOR, LOCAL_VARIABLE})
@Retention(RetentionPolicy.SOURCE)
public @interface SuppressWarnings {
String[] value();
}
它能够修饰的程序元素包括类型、属性、方法、参数、构造器、局部变量,只能存活在源码时,取值为String[]。它的作用是告诉编译器忽略指定的警告信息,它可以取的值如下所示:
| 参数 | 作用 | 原描述 |
|---|---|---|
| all | 抑制所有警告 | to suppress all warnings |
| boxing | 抑制装箱、拆箱操作时候的警告 | to suppress warnings relative to boxing/unboxing operations |
| cast | 抑制映射相关的警告 | to suppress warnings relative to cast operations |
| dep-ann | 抑制启用注释的警告 | to suppress warnings relative to deprecated annotation |
| deprecation | 抑制过期方法警告 | to suppress warnings relative to deprecation |
| fallthrough | 抑制确在switch中缺失breaks的警告 | to suppress warnings relative to missing breaks in switch statements |
| finally | 抑制finally模块没有返回的警告 | to suppress warnings relative to finally block that don’t return |
| hiding | 抑制与隐藏变数的区域变数相关的警告 | to suppress warnings relative to locals that hide variable() |
| incomplete-switch | 忽略没有完整的switch语句 | to suppress warnings relative to missing entries in a switch statement (enum case) |
| nls | 忽略非nls格式的字符 | to suppress warnings relative to non-nls string literals |
| null | 忽略对null的操作 | to suppress warnings relative to null analysis |
| rawtype | 使用generics时忽略没有指定相应的类型 | to suppress warnings relative to un-specific types when using |
| restriction | 抑制与使用不建议或禁止参照相关的警告 | to suppress warnings relative to usage of discouraged or |
| serial | 忽略在serializable类中没有声明serialVersionUID变量 | to suppress warnings relative to missing serialVersionUID field for a serializable class |
| static-access | 抑制不正确的静态访问方式警告 | to suppress warnings relative to incorrect static access |
| synthetic-access | 抑制子类没有按最优方法访问内部类的警告 | to suppress warnings relative to unoptimized access from inner classes |
| unchecked | 抑制没有进行类型检查操作的警告 | to suppress warnings relative to unchecked operations |
| unqualified-field-access | 抑制没有权限访问的域的警告 | to suppress warnings relative to field access unqualified |
| unused | 抑制没被使用过的代码的警告 | to suppress warnings relative to unused code |
元注解
上述内置注解的定义中使用了一些元注解(注解类型进行注解的注解类),在JDK 1.5中提供了4个标准的元注解:@Target,@Retention,@Documented,@Inherited, 在JDK 1.8中提供了两个元注解 @Repeatable和@Native。
元注解 - @Target
Target注解的作用是:描述注解的使用范围(即:被修饰的注解可以用在什么地方) 。
Target注解用来说明那些被它所注解的注解类可修饰的对象范围:注解可以用于修饰 packages、types(类、接口、枚举、注解类)、类成员(方法、构造方法、成员变量、枚举值)、方法参数和本地变量(如循环变量、catch参数),在定义注解类时使用了@Target 能够更加清晰的知道它能够被用来修饰哪些对象,它的取值范围定义在ElementType 枚举中。
public enum ElementType {
TYPE, // 类、接口、枚举类
FIELD, // 成员变量(包括:枚举常量)
METHOD, // 成员方法
PARAMETER, // 方法参数
CONSTRUCTOR, // 构造方法
LOCAL_VARIABLE, // 局部变量
ANNOTATION_TYPE, // 注解类
PACKAGE, // 可用于修饰:包
TYPE_PARAMETER, // 类型参数,JDK 1.8 新增
TYPE_USE // 使用类型的任何地方,JDK 1.8 新增
}
元注解 - @Retention & @RetentionTarget
Reteniton注解的作用是:描述注解保留的时间范围(即:被描述的注解在它所修饰的类中可以被保留到何时) 。
Reteniton注解用来限定那些被它所注解的注解类在注解到其他类上以后,可被保留到何时,一共有三种策略,定义在RetentionPolicy枚举中。
public enum RetentionPolicy {
SOURCE, // 源文件保留
CLASS, // 编译期保留,默认值
RUNTIME // 运行期保留,可通过反射去获取注解信息
}
为了验证应用了这三种策略的注解类有何区别,分别使用三种策略各定义一个注解类做测试。
@Retention(RetentionPolicy.SOURCE)
public @interface SourcePolicy {
}
@Retention(RetentionPolicy.CLASS)
public @interface ClassPolicy {
}
@Retention(RetentionPolicy.RUNTIME)
public @interface RuntimePolicy {
}
用定义好的三个注解类分别去注解一个方法。
public class RetentionTest {
@SourcePolicy
public void sourcePolicy() {
}
@ClassPolicy
public void classPolicy() {
}
@RuntimePolicy
public void runtimePolicy() {
}
}
通过执行 javap -verbose RetentionTest命令获取到的RetentionTest 的 class 字节码内容如下。
{
public retention.RetentionTest();
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 3: 0
public void sourcePolicy();
flags: ACC_PUBLIC
Code:
stack=0, locals=1, args_size=1
0: return
LineNumberTable:
line 7: 0
public void classPolicy();
flags: ACC_PUBLIC
Code:
stack=0, locals=1, args_size=1
0: return
LineNumberTable:
line 11: 0
RuntimeInvisibleAnnotations:
0: #11()
public void runtimePolicy();
flags: ACC_PUBLIC
Code:
stack=0, locals=1, args_size=1
0: return
LineNumberTable:
line 15: 0
RuntimeVisibleAnnotations:
0: #14()
}
从 RetentionTest 的字节码内容我们可以得出以下两点结论:
- 编译器并没有记录下 sourcePolicy() 方法的注解信息;
- 编译器分别使用了
RuntimeInvisibleAnnotations和RuntimeVisibleAnnotations属性去记录了classPolicy()方法 和runtimePolicy()方法 的注解信息;
元注解 - @Documented
Documented注解的作用是:描述在使用 javadoc 工具为类生成帮助文档时是否要保留其注解信息。
以下代码在使用Javadoc工具可以生成@TestDocAnnotation注解信息。
import java.lang.annotation.Documented;
import java.lang.annotation.ElementType;
import java.lang.annotation.Target;
@Documented
@Target({ElementType.TYPE,ElementType.METHOD})
public @interface TestDocAnnotation {
public String value() default "default";
}
@TestDocAnnotation("myMethodDoc")
public void testDoc() {
}
元注解 - @Inherited
Inherited注解的作用:被它修饰的Annotation将具有继承性。如果某个类使用了被@Inherited修饰的Annotation,则其子类将自动具有该注解。
我们来测试下这个注解:
- 定义
@Inherited注解:
@Inherited
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE,ElementType.METHOD})
public @interface TestInheritedAnnotation {
String [] values();
int number();
}
- 使用这个注解
@TestInheritedAnnotation(values = {"value"}, number = 10)
public class Person {
}
class Student extends Person{
@Test
public void test(){
Class clazz = Student.class;
Annotation[] annotations = clazz.getAnnotations();
for (Annotation annotation : annotations) {
System.out.println(annotation.toString());
}
}
}
- 输出
xxxxxxx.TestInheritedAnnotation(values=[value], number=10)
即使Student类没有显示地被注解@TestInheritedAnnotation,但是它的父类Person被注解,而且@TestInheritedAnnotation被@Inherited注解,因此Student类自动有了该注解。
元注解 - @Repeatable (Java8)
元注解 - @Native (Java8)
使用 @Native 注解修饰成员变量,则表示这个变量可以被本地代码引用,常常被代码生成工具使用。对于 @Native 注解不常使用,了解即可
注解与反射接口
定义注解后,如何获取注解中的内容呢?反射包java.lang.reflect下的AnnotatedElement接口提供这些方法。这里注意:只有注解被定义为RUNTIME后,该注解才能是运行时可见,当class文件被装载时被保存在class文件中的Annotation才会被虚拟机读取。
AnnotatedElement 接口是所有程序元素(Class、Method和Constructor)的父接口,所以程序通过反射获取了某个类的AnnotatedElement对象之后,程序就可以调用该对象的方法来访问Annotation信息。我们看下具体的先关接口
boolean isAnnotationPresent(Class<?extends Annotation> annotationClass)
判断该程序元素上是否包含指定类型的注解,存在则返回true,否则返回false。注意:此方法会忽略注解对应的注解容器。
<T extends Annotation> T getAnnotation(Class<T> annotationClass)
返回该程序元素上存在的、指定类型的注解,如果该类型注解不存在,则返回null。
Annotation[] getAnnotations()
返回该程序元素上存在的所有注解,若没有注解,返回长度为0的数组。
<T extends Annotation> T[] getAnnotationsByType(Class<T> annotationClass)
返回该程序元素上存在的、指定类型的注解数组。没有注解对应类型的注解时,返回长度为0的数组。该方法的调用者可以随意修改返回的数组,而不会对其他调用者返回的数组产生任何影响。getAnnotationsByType方法与 getAnnotation的区别在于,getAnnotationsByType会检测注解对应的重复注解容器。若程序元素为类,当前类上找不到注解,且该注解为可继承的,则会去父类上检测对应的注解。
<T extends Annotation> T getDeclaredAnnotation(Class<T> annotationClass)
返回直接存在于此元素上的所有注解。与此接口中的其他方法不同,该方法将忽略继承的注释。如果没有注释直接存在于此元素上,则返回null
<T extends Annotation> T[] getDeclaredAnnotationsByType(Class<T> annotationClass)
返回直接存在于此元素上的所有注解。与此接口中的其他方法不同,该方法将忽略继承的注释
Annotation[] getDeclaredAnnotations()
返回直接存在于此元素上的所有注解及注解对应的重复注解容器。与此接口中的其他方法不同,该方法将忽略继承的注解。如果没有注释直接存在于此元素上,则返回长度为零的一个数组。该方法的调用者可以随意修改返回的数组,而不会对其他调用者返回的数组产生任何影响。
自定义注解
当我们理解了内置注解, 元注解和获取注解的反射接口后,我们便可以开始自定义注解了。这个例子我把上述的知识点全部融入进来, 代码很简单:
- 定义自己的注解
package com.pdai.java.annotation;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface MyMethodAnnotation {
public String title() default "";
public String description() default "";
}
- 使用注解
package com.pdai.java.annotation;
import java.io.FileNotFoundException;
import java.lang.annotation.Annotation;
import java.lang.reflect.Method;
import java.util.ArrayList;
import java.util.List;
public class TestMethodAnnotation {
@Override
@MyMethodAnnotation(title = "toStringMethod", description = "override toString method")
public String toString() {
return "Override toString method";
}
@Deprecated
@MyMethodAnnotation(title = "old static method", description = "deprecated old static method")
public static void oldMethod() {
System.out.println("old method, don't use it.");
}
@SuppressWarnings({"unchecked", "deprecation"})
@MyMethodAnnotation(title = "test method", description = "suppress warning static method")
public static void genericsTest() throws FileNotFoundException {
List l = new ArrayList();
l.add("abc");
oldMethod();
}
}
- 用反射接口获取注解信息
在TestMethodAnnotation中添加Main方法进行测试:
public static void main(String[] args) {
try {
// 获取所有methods
Method[] methods = TestMethodAnnotation.class.getClassLoader()
.loadClass(("com.pdai.java.annotation.TestMethodAnnotation"))
.getMethods();
// 遍历
for (Method method : methods) {
// 方法上是否有MyMethodAnnotation注解
if (method.isAnnotationPresent(MyMethodAnnotation.class)) {
try {
// 获取并遍历方法上的所有注解
for (Annotation anno : method.getDeclaredAnnotations()) {
System.out.println("Annotation in Method '"
+ method + "' : " + anno);
}
// 获取MyMethodAnnotation对象信息
MyMethodAnnotation methodAnno = method
.getAnnotation(MyMethodAnnotation.class);
System.out.println(methodAnno.title());
} catch (Throwable ex) {
ex.printStackTrace();
}
}
}
} catch (SecurityException | ClassNotFoundException e) {
e.printStackTrace();
}
}
- 测试的输出
Annotation in Method 'public static void com.pdai.java.annotation.TestMethodAnnotation.oldMethod()' : @java.lang.Deprecated()
Annotation in Method 'public static void com.pdai.java.annotation.TestMethodAnnotation.oldMethod()' : @com.pdai.java.annotation.MyMethodAnnotation(title=old static method, description=deprecated old static method)
old static method
Annotation in Method 'public static void com.pdai.java.annotation.TestMethodAnnotation.genericsTest() throws java.io.FileNotFoundException' : @com.pdai.java.annotation.MyMethodAnnotation(title=test method, description=suppress warning static method)
test method
Annotation in Method 'public java.lang.String com.pdai.java.annotation.TestMethodAnnotation.toString()' : @com.pdai.java.annotation.MyMethodAnnotation(title=toStringMethod, description=override toString method)
toStringMethod
深入理解注解
提示
接下来,我们从其它角度深入理解注解
Java8提供了哪些新的注解?
-
@Repeatable -
ElementType.TYPE_USE -
ElementType.TYPE_PARAMETER
ElementType.TYPE_USE(此类型包括类型声明和类型参数声明,是为了方便设计者进行类型检查)包含了ElementType.TYPE(类、接口(包括注解类型)和枚举的声明)和ElementType.TYPE_PARAMETER(类型参数声明), 不妨再看个例子
// 自定义ElementType.TYPE_PARAMETER注解
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE_PARAMETER)
public @interface MyNotEmpty {
}
// 自定义ElementType.TYPE_USE注解
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE_USE)
public @interface MyNotNull {
}
// 测试类
public class TypeParameterAndTypeUseAnnotation<@MyNotEmpty T>{
//使用TYPE_PARAMETER类型,会编译不通过
// public @MyNotEmpty T test(@MyNotEmpty T a){
// new ArrayList<@MyNotEmpty String>();
// return a;
// }
//使用TYPE_USE类型,编译通过
public @MyNotNull T test2(@MyNotNull T a){
new ArrayList<@MyNotNull String>();
return a;
}
}
注解支持继承吗?
注解是不支持继承的
不能使用关键字extends来继承某个@interface,但注解在编译后,编译器会自动继承java.lang.annotation.Annotation接口.
虽然反编译后发现注解继承了Annotation接口,请记住,即使Java的接口可以实现多继承,但定义注解时依然无法使用extends关键字继承@interface。
区别于注解的继承,被注解的子类继承父类注解可以用@Inherited: 如果某个类使用了被@Inherited修饰的Annotation,则其子类将自动具有该注解。
注解实现的原理?
网上很多标注解的原理文章根本没有说到点子上。
这里推荐你两篇文章:
- https://blog.csdn.net/qq_20009015/article/details/106038023
- https://www.race604.com/annotation-processing/
注解的应用场景
配置化到注解化 - 框架的演进
Spring 框架 配置化到注解化的转变。
继承实现到注解实现 - Junit3到Junit4
一个模块的封装大多数人都是通过继承和组合等模式来实现的,但是如果结合注解将可以极大程度提高实现的优雅度(降低耦合度)。而Junit3 到Junit4的演化就是最好的一个例子。
- 被测试类
public class HelloWorld {
public void sayHello(){
System.out.println("hello....");
throw new NumberFormatException();
}
public void sayWorld(){
System.out.println("world....");
}
public String say(){
return "hello world!";
}
}
- Junit 3 实现UT
通过继承 TestCase来实现,初始化是通过Override父类方法来进行,测试方式通过test的前缀方法获取。
public class HelloWorldTest extends TestCase{
private HelloWorld hw;
@Override
protected void setUp() throws Exception {
super.setUp();
hw=new HelloWorld();
}
//1.测试没有返回值
public void testHello(){
try {
hw.sayHello();
} catch (Exception e) {
System.out.println("发生异常.....");
}
}
public void testWorld(){
hw.sayWorld();
}
//2.测试有返回值的方法
// 返回字符串
public void testSay(){
assertEquals("测试失败", hw.say(), "hello world!");
}
//返回对象
public void testObj(){
assertNull("测试对象不为空", null);
assertNotNull("测试对象为空",new String());
}
@Override
protected void tearDown() throws Exception {
super.tearDown();
hw=null;
}
}
- Junit 4 实现UT
通过定义@Before,@Test,@After等等注解来实现。
public class HelloWorldTest {
private HelloWorld hw;
@Before
public void setUp() {
hw = new HelloWorld();
}
@Test(expected=NumberFormatException.class)
// 1.测试没有返回值,有别于junit3的使用,更加方便
public void testHello() {
hw.sayHello();
}
@Test
public void testWorld() {
hw.sayWorld();
}
@Test
// 2.测试有返回值的方法
// 返回字符串
public void testSay() {
assertEquals("测试失败", hw.say(), "hello world!");
}
@Test
// 返回对象
public void testObj() {
assertNull("测试对象不为空", null);
assertNotNull("测试对象为空", new String());
}
@After
public void tearDown() throws Exception {
hw = null;
}
}
这里我们发现通过注解的方式,我们实现单元测试时将更为优雅。如果你还期望了解Junit4是如何实现运行的呢?可以看这篇文章:JUnit4源码分析运行原理在新窗口打开。
自定义注解和AOP - 通过切面实现解耦
最为常见的就是使用Spring AOP切面实现统一的操作日志管理,我这里找了一个开源项目中的例子(只展示主要代码),给你展示下如何通过注解实现解耦的。
- 自定义Log注解
@Target({ ElementType.PARAMETER, ElementType.METHOD })
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Log {
/**
* 模块
*/
public String title() default "";
/**
* 功能
*/
public BusinessType businessType() default BusinessType.OTHER;
/**
* 操作人类别
*/
public OperatorType operatorType() default OperatorType.MANAGE;
/**
* 是否保存请求的参数
*/
public boolean isSaveRequestData() default true;
}
- 实现日志的切面, 对自定义注解Log作切点进行拦截
即对注解了@Log的方法进行切点拦截,
@Aspect
@Component
public class LogAspect {
private static final Logger log = LoggerFactory.getLogger(LogAspect.class);
/**
* 配置织入点 - 自定义注解的包路径
*
*/
@Pointcut("@annotation(com.xxx.aspectj.lang.annotation.Log)")
public void logPointCut() {
}
/**
* 处理完请求后执行
*
* @param joinPoint 切点
*/
@AfterReturning(pointcut = "logPointCut()", returning = "jsonResult")
public void doAfterReturning(JoinPoint joinPoint, Object jsonResult) {
handleLog(joinPoint, null, jsonResult);
}
/**
* 拦截异常操作
*
* @param joinPoint 切点
* @param e 异常
*/
@AfterThrowing(value = "logPointCut()", throwing = "e")
public void doAfterThrowing(JoinPoint joinPoint, Exception e) {
handleLog(joinPoint, e, null);
}
protected void handleLog(final JoinPoint joinPoint, final Exception e, Object jsonResult) {
try {
// 获得注解
Log controllerLog = getAnnotationLog(joinPoint);
if (controllerLog == null) {
return;
}
// 获取当前的用户
User currentUser = ShiroUtils.getSysUser();
// *========数据库日志=========*//
OperLog operLog = new OperLog();
operLog.setStatus(BusinessStatus.SUCCESS.ordinal());
// 请求的地址
String ip = ShiroUtils.getIp();
operLog.setOperIp(ip);
// 返回参数
operLog.setJsonResult(JSONObject.toJSONString(jsonResult));
operLog.setOperUrl(ServletUtils.getRequest().getRequestURI());
if (currentUser != null) {
operLog.setOperName(currentUser.getLoginName());
if (StringUtils.isNotNull(currentUser.getDept())
&& StringUtils.isNotEmpty(currentUser.getDept().getDeptName())) {
operLog.setDeptName(currentUser.getDept().getDeptName());
}
}
if (e != null) {
operLog.setStatus(BusinessStatus.FAIL.ordinal());
operLog.setErrorMsg(StringUtils.substring(e.getMessage(), 0, 2000));
}
// 设置方法名称
String className = joinPoint.getTarget().getClass().getName();
String methodName = joinPoint.getSignature().getName();
operLog.setMethod(className + "." + methodName + "()");
// 设置请求方式
operLog.setRequestMethod(ServletUtils.getRequest().getMethod());
// 处理设置注解上的参数
getControllerMethodDescription(controllerLog, operLog);
// 保存数据库
AsyncManager.me().execute(AsyncFactory.recordOper(operLog));
} catch (Exception exp) {
// 记录本地异常日志
log.error("==前置通知异常==");
log.error("异常信息:{}", exp.getMessage());
exp.printStackTrace();
}
}
/**
* 获取注解中对方法的描述信息 用于Controller层注解
*
* @param log 日志
* @param operLog 操作日志
* @throws Exception
*/
public void getControllerMethodDescription(Log log, OperLog operLog) throws Exception {
// 设置action动作
operLog.setBusinessType(log.businessType().ordinal());
// 设置标题
operLog.setTitle(log.title());
// 设置操作人类别
operLog.setOperatorType(log.operatorType().ordinal());
// 是否需要保存request,参数和值
if (log.isSaveRequestData()) {
// 获取参数的信息,传入到数据库中。
setRequestValue(operLog);
}
}
/**
* 获取请求的参数,放到log中
*
* @param operLog
* @param request
*/
private void setRequestValue(OperLog operLog) {
Map<String, String[]> map = ServletUtils.getRequest().getParameterMap();
String params = JSONObject.toJSONString(map);
operLog.setOperParam(StringUtils.substring(params, 0, 2000));
}
/**
* 是否存在注解,如果存在就获取
*/
private Log getAnnotationLog(JoinPoint joinPoint) throws Exception {
Signature signature = joinPoint.getSignature();
MethodSignature methodSignature = (MethodSignature) signature;
Method method = methodSignature.getMethod();
if (method != null)
{
return method.getAnnotation(Log.class);
}
return null;
}
}
- 使用@Log注解
以一个简单的CRUD操作为例, 这里展示部分代码:每对“部门”进行操作就会产生一条操作日志存入数据库。
@Controller
@RequestMapping("/system/dept")
public class DeptController extends BaseController {
private String prefix = "system/dept";
@Autowired
private IDeptService deptService;
/**
* 新增保存部门
*/
@Log(title = "部门管理", businessType = BusinessType.INSERT)
@RequiresPermissions("system:dept:add")
@PostMapping("/add")
@ResponseBody
public AjaxResult addSave(@Validated Dept dept) {
if (UserConstants.DEPT_NAME_NOT_UNIQUE.equals(deptService.checkDeptNameUnique(dept))) {
return error("新增部门'" + dept.getDeptName() + "'失败,部门名称已存在");
}
return toAjax(deptService.insertDept(dept));
}
/**
* 保存
*/
@Log(title = "部门管理", businessType = BusinessType.UPDATE)
@RequiresPermissions("system:dept:edit")
@PostMapping("/edit")
@ResponseBody
public AjaxResult editSave(@Validated Dept dept) {
if (UserConstants.DEPT_NAME_NOT_UNIQUE.equals(deptService.checkDeptNameUnique(dept))) {
return error("修改部门'" + dept.getDeptName() + "'失败,部门名称已存在");
} else if(dept.getParentId().equals(dept.getDeptId())) {
return error("修改部门'" + dept.getDeptName() + "'失败,上级部门不能是自己");
}
return toAjax(deptService.updateDept(dept));
}
/**
* 删除
*/
@Log(title = "部门管理", businessType = BusinessType.DELETE)
@RequiresPermissions("system:dept:remove")
@GetMapping("/remove/{deptId}")
@ResponseBody
public AjaxResult remove(@PathVariable("deptId") Long deptId) {
if (deptService.selectDeptCount(deptId) > 0) {
return AjaxResult.warn("存在下级部门,不允许删除");
}
if (deptService.checkDeptExistUser(deptId)) {
return AjaxResult.warn("部门存在用户,不允许删除");
}
return toAjax(deptService.deleteDeptById(deptId));
}
// ...
}
同样的,你也可以看到权限管理也是通过类似的注解(
@RequiresPermissions)机制来实现的。所以我们可以看到,通过注解+AOP最终的目标是为了实现模块的解耦。
异常机制详解
Java异常是Java提供的一种识别及响应错误的一致性机制,java异常机制可以使程序中异常处理代码和正常业务代码分离,保证程序代码更加优雅,并提高程序健壮性。本文综合多篇文章后,总结了Java 异常的相关知识,希望可以提升你对Java中异常的认知效率。
异常的层次结构
异常指不期而至的各种状况,如:文件找不到、网络连接失败、非法参数等。异常是一个事件,它发生在程序运行期间,干扰了正常的指令流程。Java通 过API中Throwable类的众多子类描述各种不同的异常。因而,Java异常都是对象,是Throwable子类的实例,描述了出现在一段编码中的 错误条件。当条件生成时,错误将引发异常。
Java异常类层次结构图:
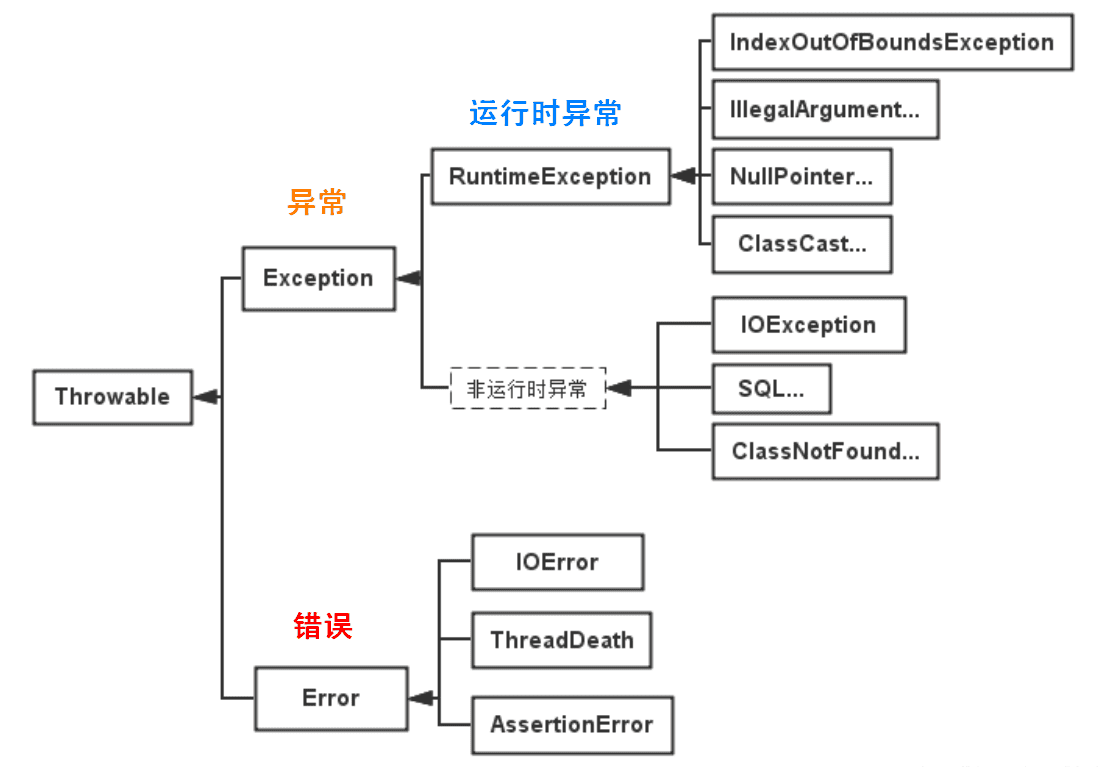
Throwable
Throwable 是 Java 语言中所有错误与异常的超类。
Throwable 包含两个子类:Error(错误)和 Exception(异常),它们通常用于指示发生了异常情况。
Throwable 包含了其线程创建时线程执行堆栈的快照,它提供了 printStackTrace() 等接口用于获取堆栈跟踪数据等信息。
Error(错误)
Error 类及其子类:程序中无法处理的错误,表示运行应用程序中出现了严重的错误。
此类错误一般表示代码运行时 JVM 出现问题。通常有 Virtual MachineError(虚拟机运行错误)、NoClassDefFoundError(类定义错误)等。比如 OutOfMemoryError:内存不足错误;StackOverflowError:栈溢出错误。此类错误发生时,JVM 将终止线程。
这些错误是不受检异常,非代码性错误。因此,当此类错误发生时,应用程序不应该去处理此类错误。按照Java惯例,我们是不应该实现任何新的Error子类的!
Exception(异常)
程序本身可以捕获并且可以处理的异常。Exception 这种异常又分为两类:运行时异常和编译时异常。
- 运行时异常
都是RuntimeException类及其子类异常,如NullPointerException(空指针异常)、IndexOutOfBoundsException(下标越界异常)等,这些异常是不检查异常,程序中可以选择捕获处理,也可以不处理。这些异常一般是由程序逻辑错误引起的,程序应该从逻辑角度尽可能避免这类异常的发生。
运行时异常的特点是Java编译器不会检查它,也就是说,当程序中可能出现这类异常,即使没有用try-catch语句捕获它,也没有用throws子句声明抛出它,也会编译通过。
- 非运行时异常 (编译异常)
是RuntimeException以外的异常,类型上都属于Exception类及其子类。从程序语法角度讲是必须进行处理的异常,如果不处理,程序就不能编译通过。如IOException、SQLException等以及用户自定义的Exception异常,一般情况下不自定义检查异常。
可查的异常(checked exceptions)和不可查的异常(unchecked exceptions)
- 可查异常(编译器要求必须处置的异常):
正确的程序在运行中,很容易出现的、情理可容的异常状况。可查异常虽然是异常状况,但在一定程度上它的发生是可以预计的,而且一旦发生这种异常状况,就必须采取某种方式进行处理。
除了RuntimeException及其子类以外,其他的Exception类及其子类都属于可查异常。这种异常的特点是Java编译器会检查它,也就是说,当程序中可能出现这类异常,要么用try-catch语句捕获它,要么用throws子句声明抛出它,否则编译不会通过。
- 不可查异常(编译器不要求强制处置的异常)
包括运行时异常(RuntimeException与其子类)和错误(Error)。
异常基础
提示
接下来我们看下异常使用的基础。
异常关键字
- try – 用于监听。将要被监听的代码(可能抛出异常的代码)放在try语句块之内,当try语句块内发生异常时,异常就被抛出。
- catch – 用于捕获异常。catch用来捕获try语句块中发生的异常。
- finally – finally语句块总是会被执行。它主要用于回收在try块里打开的物力资源(如数据库连接、网络连接和磁盘文件)。只有finally块,执行完成之后,才会回来执行try或者catch块中的return或者throw语句,如果finally中使用了return或者throw等终止方法的语句,则就不会跳回执行,直接停止。
- throw – 用于抛出异常。
- throws – 用在方法签名中,用于声明该方法可能抛出的异常。
异常的申明(throws)
在Java中,当前执行的语句必属于某个方法,Java解释器调用main方法执行开始执行程序。若方法中存在检查异常,如果不对其捕获,那必须在方法头中显式声明该异常,以便于告知方法调用者此方法有异常,需要进行处理。 在方法中声明一个异常,方法头中使用关键字throws,后面接上要声明的异常。若声明多个异常,则使用逗号分割。如下所示:
public static void method() throws IOException, FileNotFoundException{
//something statements
}
注意:若是父类的方法没有声明异常,则子类继承方法后,也不能声明异常。
通常,应该捕获那些知道如何处理的异常,将不知道如何处理的异常继续传递下去。传递异常可以在方法签名处使用 throws 关键字声明可能会抛出的异常。
private static void readFile(String filePath) throws IOException {
File file = new File(filePath);
String result;
BufferedReader reader = new BufferedReader(new FileReader(file));
while((result = reader.readLine())!=null) {
System.out.println(result);
}
reader.close();
}
Throws抛出异常的规则:
- 如果是不可查异常(unchecked exception),即Error、RuntimeException或它们的子类,那么可以不使用throws关键字来声明要抛出的异常,编译仍能顺利通过,但在运行时会被系统抛出。
- 必须声明方法可抛出的任何可查异常(checked exception)。即如果一个方法可能出现受可查异常,要么用try-catch语句捕获,要么用throws子句声明将它抛出,否则会导致编译错误
- 仅当抛出了异常,该方法的调用者才必须处理或者重新抛出该异常。当方法的调用者无力处理该异常的时候,应该继续抛出,而不是囫囵吞枣。
- 调用方法必须遵循任何可查异常的处理和声明规则。若覆盖一个方法,则不能声明与覆盖方法不同的异常。声明的任何异常必须是被覆盖方法所声明异常的同类或子类。
异常的抛出(throw)
如果代码可能会引发某种错误,可以创建一个合适的异常类实例并抛出它,这就是抛出异常。如下所示:
public static double method(int value) {
if(value == 0) {
throw new ArithmeticException("参数不能为0"); //抛出一个运行时异常
}
return 5.0 / value;
}
大部分情况下都不需要手动抛出异常,因为Java的大部分方法要么已经处理异常,要么已声明异常。所以一般都是捕获异常或者再往上抛。
有时我们会从 catch 中抛出一个异常,目的是为了改变异常的类型。多用于在多系统集成时,当某个子系统故障,异常类型可能有多种,可以用统一的异常类型向外暴露,不需暴露太多内部异常细节。
private static void readFile(String filePath) throws MyException {
try {
// code
} catch (IOException e) {
MyException ex = new MyException("read file failed.");
ex.initCause(e);
throw ex;
}
}
异常的自定义
习惯上,定义一个异常类应包含两个构造函数,一个无参构造函数和一个带有详细描述信息的构造函数(Throwable 的 toString 方法会打印这些详细信息,调试时很有用), 比如上面用到的自定义MyException:
public class MyException extends Exception {
public MyException(){ }
public MyException(String msg){
super(msg);
}
// ...
}
异常的捕获
异常捕获处理的方法通常有:
- try-catch
- try-catch-finally
- try-finally
- try-with-resource
try-catch
在一个 try-catch 语句块中可以捕获多个异常类型,并对不同类型的异常做出不同的处理
private static void readFile(String filePath) {
try {
// code
} catch (FileNotFoundException e) {
// handle FileNotFoundException
} catch (IOException e){
// handle IOException
}
}
同一个 catch 也可以捕获多种类型异常,用 | 隔开
private static void readFile(String filePath) {
try {
// code
} catch (FileNotFoundException | UnknownHostException e) {
// handle FileNotFoundException or UnknownHostException
} catch (IOException e){
// handle IOException
}
}
try-catch-finally
- 常规语法
try {
//执行程序代码,可能会出现异常
} catch(Exception e) {
//捕获异常并处理
} finally {
//必执行的代码
}
- 执行的顺序
- 当try没有捕获到异常时:try语句块中的语句逐一被执行,程序将跳过catch语句块,执行finally语句块和其后的语句;
- 当try捕获到异常,catch语句块里没有处理此异常的情况:当try语句块里的某条语句出现异常时,而没有处理此异常的catch语句块时,此异常将会抛给JVM处理,finally语句块里的语句还是会被执行,但finally语句块后的语句不会被执行;
- 当try捕获到异常,catch语句块里有处理此异常的情况:在try语句块中是按照顺序来执行的,当执行到某一条语句出现异常时,程序将跳到catch语句块,并与catch语句块逐一匹配,找到与之对应的处理程序,其他的catch语句块将不会被执行,而try语句块中,出现异常之后的语句也不会被执行,catch语句块执行完后,执行finally语句块里的语句,最后执行finally语句块后的语句;
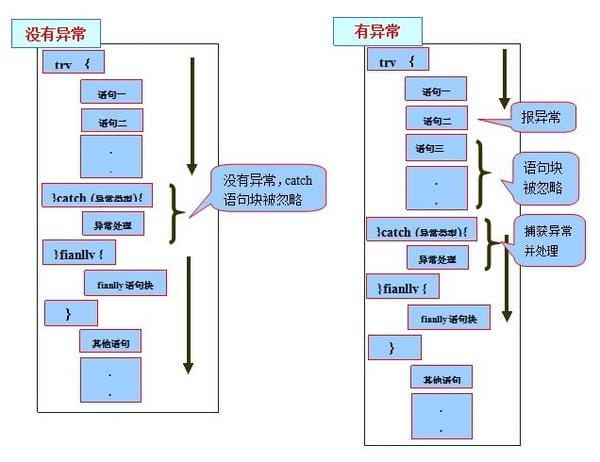
- 一个完整的例子
private static void readFile(String filePath) throws MyException {
File file = new File(filePath);
String result;
BufferedReader reader = null;
try {
reader = new BufferedReader(new FileReader(file));
while((result = reader.readLine())!=null) {
System.out.println(result);
}
} catch (IOException e) {
System.out.println("readFile method catch block.");
MyException ex = new MyException("read file failed.");
ex.initCause(e);
throw ex;
} finally {
System.out.println("readFile method finally block.");
if (null != reader) {
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
try-finally
可以直接用try-finally吗? 可以。
try块中引起异常,异常代码之后的语句不再执行,直接执行finally语句。 try块没有引发异常,则执行完try块就执行finally语句。
try-finally可用在不需要捕获异常的代码,可以保证资源在使用后被关闭。例如IO流中执行完相应操作后,关闭相应资源;使用Lock对象保证线程同步,通过finally可以保证锁会被释放;数据库连接代码时,关闭连接操作等等。
//以Lock加锁为例,演示try-finally
ReentrantLock lock = new ReentrantLock();
try {
//需要加锁的代码
} finally {
lock.unlock(); //保证锁一定被释放
}
finally遇见如下情况不会执行
- 在前面的代码中用了System.exit()退出程序。
- finally语句块中发生了异常。
- 程序所在的线程死亡。
- 关闭CPU。
try-with-resource
try-with-resource是Java 7中引入的,很容易被忽略。
上面例子中,finally 中的 close 方法也可能抛出 IOException, 从而覆盖了原始异常。JAVA 7 提供了更优雅的方式来实现资源的自动释放,自动释放的资源需要是实现了 AutoCloseable 接口的类。
- 代码实现
private static void tryWithResourceTest(){
try (Scanner scanner = new Scanner(new FileInputStream("c:/abc"),"UTF-8")){
// code
} catch (IOException e){
// handle exception
}
}
- 看下Scanner
public final class Scanner implements Iterator<String>, Closeable {
// ...
}
public interface Closeable extends AutoCloseable {
public void close() throws IOException;
}
try 代码块退出时,会自动调用 scanner.close 方法,和把 scanner.close 方法放在 finally 代码块中不同的是,若 scanner.close 抛出异常,则会被抑制,抛出的仍然为原始异常。被抑制的异常会由 addSusppressed 方法添加到原来的异常,如果想要获取被抑制的异常列表,可以调用 getSuppressed 方法来获取。
异常基础总结
- try、catch和finally都不能单独使用,只能是try-catch、try-finally或者try-catch-finally。
- try语句块监控代码,出现异常就停止执行下面的代码,然后将异常移交给catch语句块来处理。
- finally语句块中的代码一定会被执行,常用于回收资源 。
- throws:声明一个异常,告知方法调用者。
- throw :抛出一个异常,至于该异常被捕获还是继续抛出都与它无关。
Java编程思想一书中,对异常的总结。
- 在恰当的级别处理问题。(在知道该如何处理的情况下了捕获异常。)
- 解决问题并且重新调用产生异常的方法。
- 进行少许修补,然后绕过异常发生的地方继续执行。
- 用别的数据进行计算,以代替方法预计会返回的值。
- 把当前运行环境下能做的事尽量做完,然后把相同的异常重抛到更高层。
- 把当前运行环境下能做的事尽量做完,然后把不同的异常抛到更高层。
- 终止程序。
- 进行简化(如果你的异常模式使问题变得太复杂,那么用起来会非常痛苦)。
- 让类库和程序更安全。
常用的异常
在Java中提供了一些异常用来描述经常发生的错误,对于这些异常,有的需要程序员进行捕获处理或声明抛出,有的是由Java虚拟机自动进行捕获处理。Java中常见的异常类:
- RuntimeException
- java.lang.ArrayIndexOutOfBoundsException 数组索引越界异常。当对数组的索引值为负数或大于等于数组大小时抛出。
- java.lang.ArithmeticException 算术条件异常。譬如:整数除零等。
- java.lang.NullPointerException 空指针异常。当应用试图在要求使用对象的地方使用了null时,抛出该异常。譬如:调用null对象的实例方法、访问null对象的属性、计算null对象的长度、使用throw语句抛出null等等
- java.lang.ClassNotFoundException 找不到类异常。当应用试图根据字符串形式的类名构造类,而在遍历CLASSPAH之后找不到对应名称的class文件时,抛出该异常。
- java.lang.NegativeArraySizeException 数组长度为负异常
- java.lang.ArrayStoreException 数组中包含不兼容的值抛出的异常
- java.lang.SecurityException 安全性异常
- java.lang.IllegalArgumentException 非法参数异常
- IOException
- IOException:操作输入流和输出流时可能出现的异常。
- EOFException 文件已结束异常
- FileNotFoundException 文件未找到异常
- 其他
- ClassCastException 类型转换异常类
- ArrayStoreException 数组中包含不兼容的值抛出的异常
- SQLException 操作数据库异常类
- NoSuchFieldException 字段未找到异常
- NoSuchMethodException 方法未找到抛出的异常
- NumberFormatException 字符串转换为数字抛出的异常
- StringIndexOutOfBoundsException 字符串索引超出范围抛出的异常
- IllegalAccessException 不允许访问某类异常
- InstantiationException 当应用程序试图使用Class类中的newInstance()方法创建一个类的实例,而指定的类对象无法被实例化时,抛出该异常
异常实践
提示
在 Java 中处理异常并不是一个简单的事情。不仅仅初学者很难理解,即使一些有经验的开发者也需要花费很多时间来思考如何处理异常,包括需要处理哪些异常,怎样处理等等。这也是绝大多数开发团队都会制定一些规则来规范进行异常处理的原因。
当你抛出或捕获异常的时候,有很多不同的情况需要考虑,而且大部分事情都是为了改善代码的可读性或者 API 的可用性。
异常不仅仅是一个错误控制机制,也是一个通信媒介。因此,为了和同事更好的合作,一个团队必须要制定出一个最佳实践和规则,只有这样,团队成员才能理解这些通用概念,同时在工作中使用它。
这里给出几个被很多团队使用的异常处理最佳实践。
只针对不正常的情况才使用异常
异常只应该被用于不正常的条件,它们永远不应该被用于正常的控制流。《阿里手册》中:【强制】Java 类库中定义的可以通过预检查方式规避的RuntimeException异常不应该通过catch 的方式来处理,比如:NullPointerException,IndexOutOfBoundsException等等。
比如,在解析字符串形式的数字时,可能存在数字格式错误,不得通过catch Exception来实现
- 代码1
if (obj != null) {
//...
}
- 代码2
try {
obj.method();
} catch (NullPointerException e) {
//...
}
主要原因有三点:
- 异常机制的设计初衷是用于不正常的情况,所以很少会会JVM实现试图对它们的性能进行优化。所以,创建、抛出和捕获异常的开销是很昂贵的。
- 把代码放在try-catch中返回阻止了JVM实现本来可能要执行的某些特定的优化。
- 对数组进行遍历的标准模式并不会导致冗余的检查,有些现代的JVM实现会将它们优化掉。
在 finally 块中清理资源或者使用 try-with-resource 语句
当使用类似InputStream这种需要使用后关闭的资源时,一个常见的错误就是在try块的最后关闭资源。
- 错误示例
public void doNotCloseResourceInTry() {
FileInputStream inputStream = null;
try {
File file = new File("./tmp.txt");
inputStream = new FileInputStream(file);
// use the inputStream to read a file
// do NOT do this
inputStream.close();
} catch (FileNotFoundException e) {
log.error(e);
} catch (IOException e) {
log.error(e);
}
}
问题就是,只有没有异常抛出的时候,这段代码才可以正常工作。try 代码块内代码会正常执行,并且资源可以正常关闭。但是,使用 try 代码块是有原因的,一般调用一个或多个可能抛出异常的方法,而且,你自己也可能会抛出一个异常,这意味着代码可能不会执行到 try 代码块的最后部分。结果就是,你并没有关闭资源。
所以,你应该把清理工作的代码放到 finally 里去,或者使用 try-with-resource 特性。
- 方法一:使用 finally 代码块
与前面几行 try 代码块不同,finally 代码块总是会被执行。不管 try 代码块成功执行之后还是你在 catch 代码块中处理完异常后都会执行。因此,你可以确保你清理了所有打开的资源。
public void closeResourceInFinally() {
FileInputStream inputStream = null;
try {
File file = new File("./tmp.txt");
inputStream = new FileInputStream(file);
// use the inputStream to read a file
} catch (FileNotFoundException e) {
log.error(e);
} finally {
if (inputStream != null) {
try {
inputStream.close();
} catch (IOException e) {
log.error(e);
}
}
}
}
- 方法二:Java 7 的 try-with-resource 语法
如果你的资源实现了 AutoCloseable 接口,你可以使用这个语法。大多数的 Java 标准资源都继承了这个接口。当你在 try 子句中打开资源,资源会在 try 代码块执行后或异常处理后自动关闭。
public void automaticallyCloseResource() {
File file = new File("./tmp.txt");
try (FileInputStream inputStream = new FileInputStream(file);) {
// use the inputStream to read a file
} catch (FileNotFoundException e) {
log.error(e);
} catch (IOException e) {
log.error(e);
}
}
尽量使用标准的异常
代码重用是值得提倡的,这是一条通用规则,异常也不例外。
重用现有的异常有几个好处:
- 它使得你的API更加易于学习和使用,因为它与程序员原来已经熟悉的习惯用法是一致的。
- 对于用到这些API的程序而言,它们的可读性更好,因为它们不会充斥着程序员不熟悉的异常。
- 异常类越少,意味着内存占用越小,并且转载这些类的时间开销也越小。
Java标准异常中有几个是经常被使用的异常。如下表格:
| 异常 | 使用场合 |
|---|---|
| IllegalArgumentException | 参数的值不合适 |
| IllegalStateException | 参数的状态不合适 |
| NullPointerException | 在null被禁止的情况下参数值为null |
| IndexOutOfBoundsException | 下标越界 |
| ConcurrentModificationException | 在禁止并发修改的情况下,对象检测到并发修改 |
| UnsupportedOperationException | 对象不支持客户请求的方法 |
虽然它们是Java平台库迄今为止最常被重用的异常,但是,在许可的条件下,其它的异常也可以被重用。例如,如果你要实现诸如复数或者矩阵之类的算术对象,那么重用ArithmeticException和NumberFormatException将是非常合适的。如果一个异常满足你的需要,则不要犹豫,使用就可以,不过你一定要确保抛出异常的条件与该异常的文档中描述的条件一致。这种重用必须建立在语义的基础上,而不是名字的基础上。
最后,一定要清楚,选择重用哪一种异常并没有必须遵循的规则。例如,考虑纸牌对象的情形,假设有一个用于发牌操作的方法,它的参数(handSize)是发一手牌的纸牌张数。假设调用者在这个参数中传递的值大于整副牌的剩余张数。那么这种情形既可以被解释为IllegalArgumentException(handSize的值太大),也可以被解释为IllegalStateException(相对客户的请求而言,纸牌对象的纸牌太少)。
对异常进行文档说明
当在方法上声明抛出异常时,也需要进行文档说明。目的是为了给调用者提供尽可能多的信息,从而可以更好地避免或处理异常。
在 Javadoc 添加 @throws 声明,并且描述抛出异常的场景。
/**
* Method description
*
* @throws MyBusinessException - businuess exception description
*/
public void doSomething(String input) throws MyBusinessException {
// ...
}
同时,在抛出MyBusinessException 异常时,需要尽可能精确地描述问题和相关信息,这样无论是打印到日志中还是在监控工具中,都能够更容易被人阅读,从而可以更好地定位具体错误信息、错误的严重程度等。
优先捕获最具体的异常
大多数 IDE 都可以帮助你实现这个最佳实践。当你尝试首先捕获较不具体的异常时,它们会报告无法访问的代码块。
但问题在于,只有匹配异常的第一个 catch 块会被执行。 因此,如果首先捕获 IllegalArgumentException ,则永远不会到达应该处理更具体的 NumberFormatException 的 catch 块,因为它是 IllegalArgumentException 的子类。
总是优先捕获最具体的异常类,并将不太具体的 catch 块添加到列表的末尾。
你可以在下面的代码片断中看到这样一个 try-catch 语句的例子。 第一个 catch 块处理所有 NumberFormatException 异常,第二个处理所有非 NumberFormatException 异常的IllegalArgumentException 异常。
public void catchMostSpecificExceptionFirst() {
try {
doSomething("A message");
} catch (NumberFormatException e) {
log.error(e);
} catch (IllegalArgumentException e) {
log.error(e)
}
}
不要捕获 Throwable 类
Throwable 是所有异常和错误的超类。你可以在 catch 子句中使用它,但是你永远不应该这样做!
如果在 catch 子句中使用 Throwable ,它不仅会捕获所有异常,也将捕获所有的错误。JVM 抛出错误,指出不应该由应用程序处理的严重问题。 典型的例子是 OutOfMemoryError 或者 StackOverflowError 。两者都是由应用程序控制之外的情况引起的,无法处理。
所以,最好不要捕获 Throwable ,除非你确定自己处于一种特殊的情况下能够处理错误。
public void doNotCatchThrowable() {
try {
// do something
} catch (Throwable t) {
// don't do this!
}
}
不要忽略异常
很多时候,开发者很有自信不会抛出异常,因此写了一个catch块,但是没有做任何处理或者记录日志。
public void doNotIgnoreExceptions() {
try {
// do something
} catch (NumberFormatException e) {
// this will never happen
}
}
但现实是经常会出现无法预料的异常,或者无法确定这里的代码未来是不是会改动(删除了阻止异常抛出的代码),而此时由于异常被捕获,使得无法拿到足够的错误信息来定位问题。
合理的做法是至少要记录异常的信息。
public void logAnException() {
try {
// do something
} catch (NumberFormatException e) {
log.error("This should never happen: " + e); // see this line
}
}
不要记录并抛出异常
这可能是本文中最常被忽略的最佳实践。
可以发现很多代码甚至类库中都会有捕获异常、记录日志并再次抛出的逻辑。如下:
try {
new Long("xyz");
} catch (NumberFormatException e) {
log.error(e);
throw e;
}
这个处理逻辑看着是合理的。但这经常会给同一个异常输出多条日志。如下:
17:44:28,945 ERROR TestExceptionHandling:65 - java.lang.NumberFormatException: For input string: "xyz"
Exception in thread "main" java.lang.NumberFormatException: For input string: "xyz"
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Long.parseLong(Long.java:589)
at java.lang.Long.(Long.java:965)
at com.stackify.example.TestExceptionHandling.logAndThrowException(TestExceptionHandling.java:63)
at com.stackify.example.TestExceptionHandling.main(TestExceptionHandling.java:58)
如上所示,后面的日志也没有附加更有用的信息。如果想要提供更加有用的信息,那么可以将异常包装为自定义异常。
public void wrapException(String input) throws MyBusinessException {
try {
// do something
} catch (NumberFormatException e) {
throw new MyBusinessException("A message that describes the error.", e);
}
}
因此,仅仅当想要处理异常时才去捕获,否则只需要在方法签名中声明让调用者去处理。
包装异常时不要抛弃原始的异常
捕获标准异常并包装为自定义异常是一个很常见的做法。这样可以添加更为具体的异常信息并能够做针对的异常处理。 在你这样做时,请确保将原始异常设置为原因(注:参考下方代码 NumberFormatException e 中的原始异常 e )。Exception 类提供了特殊的构造函数方法,它接受一个 Throwable 作为参数。否则,你将会丢失堆栈跟踪和原始异常的消息,这将会使分析导致异常的异常事件变得困难。
public void wrapException(String input) throws MyBusinessException {
try {
// do something
} catch (NumberFormatException e) {
throw new MyBusinessException("A message that describes the error.", e);
}
}
不要使用异常控制程序的流程
不应该使用异常控制应用的执行流程,例如,本应该使用if语句进行条件判断的情况下,你却使用异常处理,这是非常不好的习惯,会严重影响应用的性能。
不要在finally块中使用return。
try块中的return语句执行成功后,并不马上返回,而是继续执行finally块中的语句,如果此处存在return语句,则在此直接返回,无情丢弃掉try块中的返回点。
如下是一个反例:
private int x = 0;
public int checkReturn() {
try {
// x等于1,此处不返回
return ++x;
} finally {
// 返回的结果是2
return ++x;
}
}
深入理解异常
JVM处理异常的机制?
提到JVM处理异常的机制,就需要提及Exception Table,以下称为异常表。我们暂且不急于介绍异常表,先看一个简单的 Java 处理异常的小例子。
public static void simpleTryCatch() {
try {
testNPE();
} catch (Exception e) {
e.printStackTrace();
}
}
上面的代码是一个很简单的例子,用来捕获处理一个潜在的空指针异常。
当然如果只是看简简单单的代码,我们很难看出什么高深之处,更没有了今天文章要谈论的内容。
所以这里我们需要借助一把神兵利器,它就是javap,一个用来拆解class文件的工具,和javac一样由JDK提供。
然后我们使用javap来分析这段代码(需要先使用javac编译)
//javap -c Main
public static void simpleTryCatch();
Code:
0: invokestatic #3 // Method testNPE:()V
3: goto 11
6: astore_0
7: aload_0
8: invokevirtual #5 // Method java/lang/Exception.printStackTrace:()V
11: return
Exception table:
from to target type
0 3 6 Class java/lang/Exception
看到上面的代码,应该会有会心一笑,因为终于看到了Exception table,也就是我们要研究的异常表。
异常表中包含了一个或多个异常处理者(Exception Handler)的信息,这些信息包含如下
- from 可能发生异常的起始点
- to 可能发生异常的结束点
- target 上述from和to之前发生异常后的异常处理者的位置
- type 异常处理者处理的异常的类信息
那么异常表用在什么时候呢
答案是异常发生的时候,当一个异常发生时
- 1.JVM会在当前出现异常的方法中,查找异常表,是否有合适的处理者来处理
- 2.如果当前方法异常表不为空,并且异常符合处理者的from和to节点,并且type也匹配,则JVM调用位于target的调用者来处理。
- 3.如果上一条未找到合理的处理者,则继续查找异常表中的剩余条目
- 4.如果当前方法的异常表无法处理,则向上查找(弹栈处理)刚刚调用该方法的调用处,并重复上面的操作。
- 5.如果所有的栈帧被弹出,仍然没有处理,则抛给当前的Thread,Thread则会终止。
- 6.如果当前Thread为最后一个非守护线程,且未处理异常,则会导致JVM终止运行。
以上就是JVM处理异常的一些机制。
try catch -finally
除了简单的try-catch外,我们还常常和finally做结合使用。比如这样的代码
public static void simpleTryCatchFinally() {
try {
testNPE();
} catch (Exception e) {
e.printStackTrace();
} finally {
System.out.println("Finally");
}
}
同样我们使用javap分析一下代码
public static void simpleTryCatchFinally();
Code:
0: invokestatic #3 // Method testNPE:()V
3: getstatic #6 // Field java/lang/System.out:Ljava/io/PrintStream;
6: ldc #7 // String Finally
8: invokevirtual #8 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
11: goto 41
14: astore_0
15: aload_0
16: invokevirtual #5 // Method java/lang/Exception.printStackTrace:()V
19: getstatic #6 // Field java/lang/System.out:Ljava/io/PrintStream;
22: ldc #7 // String Finally
24: invokevirtual #8 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
27: goto 41
30: astore_1
31: getstatic #6 // Field java/lang/System.out:Ljava/io/PrintStream;
34: ldc #7 // String Finally
36: invokevirtual #8 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
39: aload_1
40: athrow
41: return
Exception table:
from to target type
0 3 14 Class java/lang/Exception
0 3 30 any
14 19 30 any
和之前有所不同,这次异常表中,有三条数据,而我们仅仅捕获了一个Exception, 异常表的后两个item的type为any; 上面的三条异常表item的意思为:
- 如果0到3之间,发生了Exception类型的异常,调用14位置的异常处理者。
- 如果0到3之间,无论发生什么异常,都调用30位置的处理者
- 如果14到19之间(即catch部分),不论发生什么异常,都调用30位置的处理者。
再次分析上面的Java代码,finally里面的部分已经被提取到了try部分和catch部分。我们再次调一下代码来看一下
public static void simpleTryCatchFinally();
Code:
//try 部分提取finally代码,如果没有异常发生,则执行输出finally操作,直至goto到41位置,执行返回操作。
0: invokestatic #3 // Method testNPE:()V
3: getstatic #6 // Field java/lang/System.out:Ljava/io/PrintStream;
6: ldc #7 // String Finally
8: invokevirtual #8 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
11: goto 41
//catch部分提取finally代码,如果没有异常发生,则执行输出finally操作,直至执行got到41位置,执行返回操作。
14: astore_0
15: aload_0
16: invokevirtual #5 // Method java/lang/Exception.printStackTrace:()V
19: getstatic #6 // Field java/lang/System.out:Ljava/io/PrintStream;
22: ldc #7 // String Finally
24: invokevirtual #8 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
27: goto 41
//finally部分的代码如果被调用,有可能是try部分,也有可能是catch部分发生异常。
30: astore_1
31: getstatic #6 // Field java/lang/System.out:Ljava/io/PrintStream;
34: ldc #7 // String Finally
36: invokevirtual #8 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
39: aload_1
40: athrow //如果异常没有被catch捕获,而是到了这里,执行完finally的语句后,仍然要把这个异常抛出去,传递给调用处。
41: return
Catch先后顺序的问题
我们在代码中的catch的顺序决定了异常处理者在异常表的位置,所以,越是具体的异常要先处理,否则就会出现下面的问题
private static void misuseCatchException() {
try {
testNPE();
} catch (Throwable t) {
t.printStackTrace();
} catch (Exception e) { //error occurs during compilings with tips Exception Java.lang.Exception has already benn caught.
e.printStackTrace();
}
}
这段代码会导致编译失败,因为先捕获Throwable后捕获Exception,会导致后面的catch永远无法被执行。
Return 和finally的问题
这算是我们扩展的一个相对比较极端的问题,就是类似这样的代码,既有return,又有finally,那么finally导致会不会执行
public static String tryCatchReturn() {
try {
testNPE();
return "OK";
} catch (Exception e) {
return "ERROR";
} finally {
System.out.println("tryCatchReturn");
}
}
答案是finally会执行,那么还是使用上面的方法,我们来看一下为什么finally会执行。
public static java.lang.String tryCatchReturn();
Code:
0: invokestatic #3 // Method testNPE:()V
3: ldc #6 // String OK
5: astore_0
6: getstatic #7 // Field java/lang/System.out:Ljava/io/PrintStream;
9: ldc #8 // String tryCatchReturn
11: invokevirtual #9 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
14: aload_0
15: areturn 返回OK字符串,areturn意思为return a reference from a method
16: astore_0
17: ldc #10 // String ERROR
19: astore_1
20: getstatic #7 // Field java/lang/System.out:Ljava/io/PrintStream;
23: ldc #8 // String tryCatchReturn
25: invokevirtual #9 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
28: aload_1
29: areturn //返回ERROR字符串
30: astore_2
31: getstatic #7 // Field java/lang/System.out:Ljava/io/PrintStream;
34: ldc #8 // String tryCatchReturn
36: invokevirtual #9 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
39: aload_2
40: athrow 如果catch有未处理的异常,抛出去。
异常是否耗时?为什么会耗时?
说用异常慢,首先来看看异常慢在哪里?有多慢?下面的测试用例简单的测试了建立对象、建立异常对象、抛出并接住异常对象三者的耗时对比:
public class ExceptionTest {
private int testTimes;
public ExceptionTest(int testTimes) {
this.testTimes = testTimes;
}
public void newObject() {
long l = System.nanoTime();
for (int i = 0; i < testTimes; i++) {
new Object();
}
System.out.println("建立对象:" + (System.nanoTime() - l));
}
public void newException() {
long l = System.nanoTime();
for (int i = 0; i < testTimes; i++) {
new Exception();
}
System.out.println("建立异常对象:" + (System.nanoTime() - l));
}
public void catchException() {
long l = System.nanoTime();
for (int i = 0; i < testTimes; i++) {
try {
throw new Exception();
} catch (Exception e) {
}
}
System.out.println("建立、抛出并接住异常对象:" + (System.nanoTime() - l));
}
public static void main(String[] args) {
ExceptionTest test = new ExceptionTest(10000);
test.newObject();
test.newException();
test.catchException();
}
}
运行结果:
建立对象:575817
建立异常对象:9589080
建立、抛出并接住异常对象:47394475
建立一个异常对象,是建立一个普通Object耗时的约20倍(实际上差距会比这个数字更大一些,因为循环也占用了时间,追求精确的读者可以再测一下空循环的耗时然后在对比前减掉这部分),而抛出、接住一个异常对象,所花费时间大约是建立异常对象的4倍。
那占用时间的“大头”:抛出、接住异常,系统到底做了什么事情?请参考这篇文章:
反射机制详解
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。Java反射机制在框架设计中极为广泛,需要深入理解。本文综合多篇文章后,总结了Java 反射的相关知识,希望可以提升你对Java中反射的认知效率。@pdai
反射基础
RTTI(Run-Time Type Identification)运行时类型识别。在《Thinking in Java》一书第十四章中有提到,其作用是在运行时识别一个对象的类型和类的信息。主要有两种方式:一种是“传统的”RTTI,它假定我们在编译时已经知道了所有的类型;另一种是“反射”机制,它允许我们在运行时发现和使用类的信息。
反射就是把java类中的各种成分映射成一个个的Java对象
例如:一个类有:成员变量、方法、构造方法、包等等信息,利用反射技术可以对一个类进行解剖,把个个组成部分映射成一个个对象。
这里我们首先需要理解 Class类,以及类的加载机制; 然后基于此我们如何通过反射获取Class类以及类中的成员变量、方法、构造方法等。
Class类
Class类,Class类也是一个实实在在的类,存在于JDK的java.lang包中。Class类的实例表示java应用运行时的类(class ans enum)或接口(interface and annotation)(每个java类运行时都在JVM里表现为一个class对象,可通过类名.class、类型.getClass()、Class.forName("类名")等方法获取class对象)。数组同样也被映射为class 对象的一个类,所有具有相同元素类型和维数的数组都共享该 Class 对象。基本类型boolean,byte,char,short,int,long,float,double和关键字void同样表现为 class 对象。
public final class Class<T> implements java.io.Serializable,
GenericDeclaration,
Type,
AnnotatedElement {
private static final int ANNOTATION= 0x00002000;
private static final int ENUM = 0x00004000;
private static final int SYNTHETIC = 0x00001000;
private static native void registerNatives();
static {
registerNatives();
}
/*
* Private constructor. Only the Java Virtual Machine creates Class objects. //私有构造器,只有JVM才能调用创建Class对象
* This constructor is not used and prevents the default constructor being
* generated.
*/
private Class(ClassLoader loader) {
// Initialize final field for classLoader. The initialization value of non-null
// prevents future JIT optimizations from assuming this final field is null.
classLoader = loader;
}
到这我们也就可以得出以下几点信息:
- Class类也是类的一种,与class关键字是不一样的。
- 手动编写的类被编译后会产生一个Class对象,其表示的是创建的类的类型信息,而且这个Class对象保存在同名.class的文件中(字节码文件)
- 每个通过关键字class标识的类,在内存中有且只有一个与之对应的Class对象来描述其类型信息,无论创建多少个实例对象,其依据的都是用一个Class对象。
- Class类只存私有构造函数,因此对应Class对象只能有JVM创建和加载
- Class类的对象作用是运行时提供或获得某个对象的类型信息,这点对于反射技术很重要(关于反射稍后分析)。
类加载
类加载机制和类字节码技术可以参考如下两篇文章:
- JVM基础 - 类字节码详解
- 源代码通过编译器编译为字节码,再通过类加载子系统进行加载到JVM中运行
- JVM基础 - Java 类加载机制
- 这篇文章将带你深入理解Java 类加载机制
其中,这里我们需要回顾的是:
- 类加载机制流程

- 类的加载
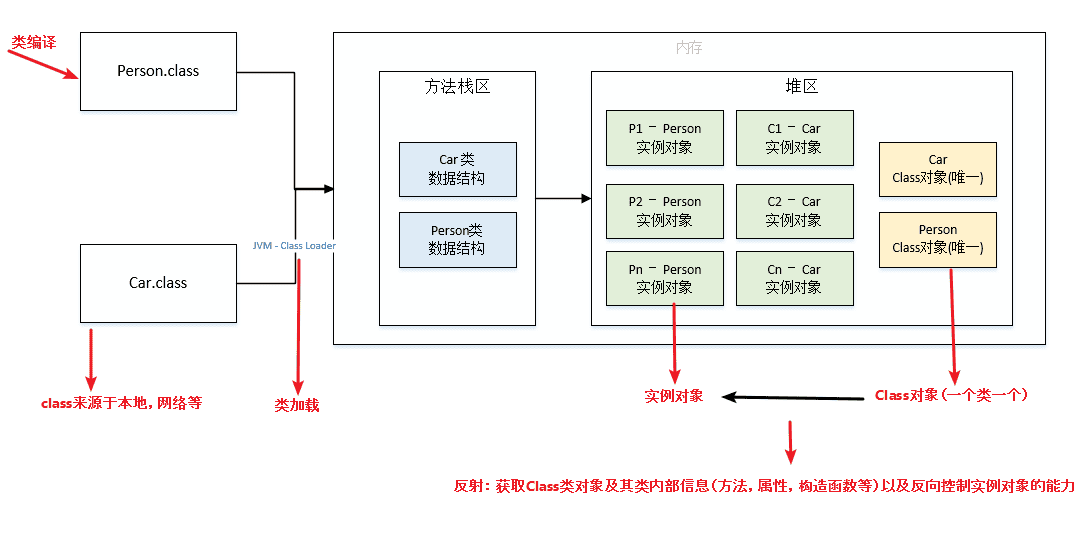
反射的使用
提示
基于此我们如何通过反射获取Class类对象以及类中的成员变量、方法、构造方法等
在Java中,Class类与java.lang.reflect类库一起对反射技术进行了全力的支持。在反射包中,我们常用的类主要有Constructor类表示的是Class 对象所表示的类的构造方法,利用它可以在运行时动态创建对象、Field表示Class对象所表示的类的成员变量,通过它可以在运行时动态修改成员变量的属性值(包含private)、Method表示Class对象所表示的类的成员方法,通过它可以动态调用对象的方法(包含private),下面将对这几个重要类进行分别说明。
Class类对象的获取
在类加载的时候,jvm会创建一个class对象
class对象是可以说是反射中最常用的,获取class对象的方式的主要有三种
- 根据类名:类名.class
- 根据对象:对象.getClass()
- 根据全限定类名:Class.forName(全限定类名)
@Test
public void classTest() throws Exception {
// 获取Class对象的三种方式
logger.info("根据类名: \t" + User.class);
logger.info("根据对象: \t" + new User().getClass());
logger.info("根据全限定类名:\t" + Class.forName("com.test.User"));
// 常用的方法
logger.info("获取全限定类名:\t" + userClass.getName());
logger.info("获取类名:\t" + userClass.getSimpleName());
logger.info("实例化:\t" + userClass.newInstance());
}
// ...
package com.test;
public class User {
private String name = "init";
private int age;
public User() {}
public User(String name, int age) {
super();
this.name = name;
this.age = age;
}
private String getName() {
return name;
}
private void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "User [name=" + name + ", age=" + age + "]";
}
}
输出结果:
根据类名: class com.test.User
根据对象: class com.test.User
根据全限定类名: class com.test.User
获取全限定类名: com.test.User
获取类名: User
实例化: User [name=init, age=0]
- 再来看看 Class类的方法
| 方法名 | 说明 |
|---|---|
| forName() | (1)获取Class对象的一个引用,但引用的类还没有加载(该类的第一个对象没有生成)就加载了这个类。 |
| (2)为了产生Class引用,forName()立即就进行了初始化。 | |
| Object-getClass() | 获取Class对象的一个引用,返回表示该对象的实际类型的Class引用。 |
| getName() | 取全限定的类名(包括包名),即类的完整名字。 |
| getSimpleName() | 获取类名(不包括包名) |
| getCanonicalName() | 获取全限定的类名(包括包名) |
| isInterface() | 判断Class对象是否是表示一个接口 |
| getInterfaces() | 返回Class对象数组,表示Class对象所引用的类所实现的所有接口。 |
| getSupercalss() | 返回Class对象,表示Class对象所引用的类所继承的直接基类。应用该方法可在运行时发现一个对象完整的继承结构。 |
| newInstance() | 返回一个Oject对象,是实现“虚拟构造器”的一种途径。使用该方法创建的类,必须带有无参的构造器。 |
| getFields() | 获得某个类的所有的公共(public)的字段,包括继承自父类的所有公共字段。 类似的还有getMethods和getConstructors。 |
| getDeclaredFields | 获得某个类的自己声明的字段,即包括public、private和proteced,默认但是不包括父类声明的任何字段。类似的还有getDeclaredMethods和getDeclaredConstructors。 |
简单测试下(这里例子源于https://blog.csdn.net/mcryeasy/article/details/52344729)
package com.cry;
import java.lang.reflect.Field;
interface I1 {
}
interface I2 {
}
class Cell{
public int mCellPublic;
}
class Animal extends Cell{
private int mAnimalPrivate;
protected int mAnimalProtected;
int mAnimalDefault;
public int mAnimalPublic;
private static int sAnimalPrivate;
protected static int sAnimalProtected;
static int sAnimalDefault;
public static int sAnimalPublic;
}
class Dog extends Animal implements I1, I2 {
private int mDogPrivate;
public int mDogPublic;
protected int mDogProtected;
private int mDogDefault;
private static int sDogPrivate;
protected static int sDogProtected;
static int sDogDefault;
public static int sDogPublic;
}
public class Test {
public static void main(String[] args) throws IllegalAccessException, InstantiationException {
Class<Dog> dog = Dog.class;
//类名打印
System.out.println(dog.getName()); //com.cry.Dog
System.out.println(dog.getSimpleName()); //Dog
System.out.println(dog.getCanonicalName());//com.cry.Dog
//接口
System.out.println(dog.isInterface()); //false
for (Class iI : dog.getInterfaces()) {
System.out.println(iI);
}
/*
interface com.cry.I1
interface com.cry.I2
*/
//父类
System.out.println(dog.getSuperclass());//class com.cry.Animal
//创建对象
Dog d = dog.newInstance();
//字段
for (Field f : dog.getFields()) {
System.out.println(f.getName());
}
/*
mDogPublic
sDogPublic
mAnimalPublic
sAnimalPublic
mCellPublic //父类的父类的公共字段也打印出来了
*/
System.out.println("---------");
for (Field f : dog.getDeclaredFields()) {
System.out.println(f.getName());
}
/** 只有自己类声明的字段
mDogPrivate
mDogPublic
mDogProtected
mDogDefault
sDogPrivate
sDogProtected
sDogDefault
sDogPublic
*/
}
}
getName、getCanonicalName与getSimpleName的区别:
- getSimpleName:只获取类名
- getName:类的全限定名,jvm中Class的表示,可以用于动态加载Class对象,例如Class.forName。
- getCanonicalName:返回更容易理解的表示,主要用于输出(toString)或log打印,大多数情况下和getName一样,但是在内部类、数组等类型的表示形式就不同了。
package com.cry;
public class Test {
private class inner{
}
public static void main(String[] args) throws ClassNotFoundException {
//普通类
System.out.println(Test.class.getSimpleName()); //Test
System.out.println(Test.class.getName()); //com.cry.Test
System.out.println(Test.class.getCanonicalName()); //com.cry.Test
//内部类
System.out.println(inner.class.getSimpleName()); //inner
System.out.println(inner.class.getName()); //com.cry.Test$inner
System.out.println(inner.class.getCanonicalName()); //com.cry.Test.inner
//数组
System.out.println(args.getClass().getSimpleName()); //String[]
System.out.println(args.getClass().getName()); //[Ljava.lang.String;
System.out.println(args.getClass().getCanonicalName()); //java.lang.String[]
//我们不能用getCanonicalName去加载类对象,必须用getName
//Class.forName(inner.class.getCanonicalName()); 报错
Class.forName(inner.class.getName());
}
}
Constructor类及其用法
Constructor类存在于反射包(java.lang.reflect)中,反映的是Class 对象所表示的类的构造方法。
获取Constructor对象是通过Class类中的方法获取的,Class类与Constructor相关的主要方法如下:
| 方法返回值 | 方法名称 | 方法说明 |
|---|---|---|
static Class<?> | forName(String className) | 返回与带有给定字符串名的类或接口相关联的 Class 对象。 |
| Constructor | getConstructor(Class<?>... parameterTypes) | 返回指定参数类型、具有public访问权限的构造函数对象 |
Constructor<?>[] | getConstructors() | 返回所有具有public访问权限的构造函数的Constructor对象数组 |
| Constructor | getDeclaredConstructor(Class<?>... parameterTypes) | 返回指定参数类型、所有声明的(包括private)构造函数对象 |
Constructor<?>[] | getDeclaredConstructors() | 返回所有声明的(包括private)构造函数对象 |
| T | newInstance() | 调用无参构造器创建此 Class 对象所表示的类的一个新实例。 |
下面看一个简单例子来了解Constructor对象的使用:
public class ConstructionTest implements Serializable {
public static void main(String[] args) throws Exception {
Class<?> clazz = null;
//获取Class对象的引用
clazz = Class.forName("com.example.javabase.User");
//第一种方法,实例化默认构造方法,User必须无参构造函数,否则将抛异常
User user = (User) clazz.newInstance();
user.setAge(20);
user.setName("Jack");
System.out.println(user);
System.out.println("--------------------------------------------");
//获取带String参数的public构造函数
Constructor cs1 =clazz.getConstructor(String.class);
//创建User
User user1= (User) cs1.newInstance("hiway");
user1.setAge(22);
System.out.println("user1:"+user1.toString());
System.out.println("--------------------------------------------");
//取得指定带int和String参数构造函数,该方法是私有构造private
Constructor cs2=clazz.getDeclaredConstructor(int.class,String.class);
//由于是private必须设置可访问
cs2.setAccessible(true);
//创建user对象
User user2= (User) cs2.newInstance(25,"hiway2");
System.out.println("user2:"+user2.toString());
System.out.println("--------------------------------------------");
//获取所有构造包含private
Constructor<?> cons[] = clazz.getDeclaredConstructors();
// 查看每个构造方法需要的参数
for (int i = 0; i < cons.length; i++) {
//获取构造函数参数类型
Class<?> clazzs[] = cons[i].getParameterTypes();
System.out.println("构造函数["+i+"]:"+cons[i].toString() );
System.out.print("参数类型["+i+"]:(");
for (int j = 0; j < clazzs.length; j++) {
if (j == clazzs.length - 1)
System.out.print(clazzs[j].getName());
else
System.out.print(clazzs[j].getName() + ",");
}
System.out.println(")");
}
}
}
class User {
private int age;
private String name;
public User() {
super();
}
public User(String name) {
super();
this.name = name;
}
/**
* 私有构造
* @param age
* @param name
*/
private User(int age, String name) {
super();
this.age = age;
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "User{" +
"age=" + age +
", name='" + name + '\'' +
'}';
}
}
输出结果
/* output
User{age=20, name='Jack'}
--------------------------------------------
user1:User{age=22, name='hiway'}
--------------------------------------------
user2:User{age=25, name='hiway2'}
--------------------------------------------
构造函数[0]:private com.example.javabase.User(int,java.lang.String)
参数类型[0]:(int,java.lang.String)
构造函数[1]:public com.example.javabase.User(java.lang.String)
参数类型[1]:(java.lang.String)
构造函数[2]:public com.example.javabase.User()
参数类型[2]:()
关于Constructor类本身一些常用方法如下(仅部分,其他可查API)
| 方法返回值 | 方法名称 | 方法说明 |
|---|---|---|
| Class | getDeclaringClass() | 返回 Class 对象,该对象表示声明由此 Constructor 对象表示的构造方法的类,其实就是返回真实类型(不包含参数) |
| Type[] | getGenericParameterTypes() | 按照声明顺序返回一组 Type 对象,返回的就是 Constructor对象构造函数的形参类型。 |
| String | getName() | 以字符串形式返回此构造方法的名称。 |
Class<?>[] | getParameterTypes() | 按照声明顺序返回一组 Class 对象,即返回Constructor 对象所表示构造方法的形参类型 |
| T | newInstance(Object... initargs) | 使用此 Constructor对象表示的构造函数来创建新实例 |
| String | toGenericString() | 返回描述此 Constructor 的字符串,其中包括类型参数。 |
代码演示如下:
Constructor cs3 = clazz.getDeclaredConstructor(int.class,String.class);
System.out.println("-----getDeclaringClass-----");
Class uclazz=cs3.getDeclaringClass();
//Constructor对象表示的构造方法的类
System.out.println("构造方法的类:"+uclazz.getName());
System.out.println("-----getGenericParameterTypes-----");
//对象表示此 Constructor 对象所表示的方法的形参类型
Type[] tps=cs3.getGenericParameterTypes();
for (Type tp:tps) {
System.out.println("参数名称tp:"+tp);
}
System.out.println("-----getParameterTypes-----");
//获取构造函数参数类型
Class<?> clazzs[] = cs3.getParameterTypes();
for (Class claz:clazzs) {
System.out.println("参数名称:"+claz.getName());
}
System.out.println("-----getName-----");
//以字符串形式返回此构造方法的名称
System.out.println("getName:"+cs3.getName());
System.out.println("-----getoGenericString-----");
//返回描述此 Constructor 的字符串,其中包括类型参数。
System.out.println("getoGenericString():"+cs3.toGenericString());
输出结果
-----getDeclaringClass-----
构造方法的类:com.example.javabase.User
-----getGenericParameterTypes-----
参数名称tp:int
参数名称tp:class java.lang.String
-----getParameterTypes-----
参数名称:int
参数名称:java.lang.String
-----getName-----
getName:com.example.javabase.User
-----getoGenericString-----
getoGenericString():private com.example.javabase.User(int,java.lang.String)
Field类及其用法
Field 提供有关类或接口的单个字段的信息,以及对它的动态访问权限。反射的字段可能是一个类(静态)字段或实例字段。
同样的道理,我们可以通过Class类的提供的方法来获取代表字段信息的Field对象,Class类与Field对象相关方法如下:
| 方法返回值 | 方法名称 | 方法说明 |
|---|---|---|
| Field | getDeclaredField(String name) | 获取指定name名称的(包含private修饰的)字段,不包括继承的字段 |
| Field[] | getDeclaredFields() | 获取Class对象所表示的类或接口的所有(包含private修饰的)字段,不包括继承的字段 |
| Field | getField(String name) | 获取指定name名称、具有public修饰的字段,包含继承字段 |
| Field[] | getFields() | 获取修饰符为public的字段,包含继承字段 |
下面的代码演示了上述方法的使用过程
public class ReflectField {
public static void main(String[] args) throws ClassNotFoundException, NoSuchFieldException {
Class<?> clazz = Class.forName("reflect.Student");
//获取指定字段名称的Field类,注意字段修饰符必须为public而且存在该字段,
// 否则抛NoSuchFieldException
Field field = clazz.getField("age");
System.out.println("field:"+field);
//获取所有修饰符为public的字段,包含父类字段,注意修饰符为public才会获取
Field fields[] = clazz.getFields();
for (Field f:fields) {
System.out.println("f:"+f.getDeclaringClass());
}
System.out.println("================getDeclaredFields====================");
//获取当前类所字段(包含private字段),注意不包含父类的字段
Field fields2[] = clazz.getDeclaredFields();
for (Field f:fields2) {
System.out.println("f2:"+f.getDeclaringClass());
}
//获取指定字段名称的Field类,可以是任意修饰符的自动,注意不包含父类的字段
Field field2 = clazz.getDeclaredField("desc");
System.out.println("field2:"+field2);
}
/**
输出结果:
field:public int reflect.Person.age
f:public java.lang.String reflect.Student.desc
f:public int reflect.Person.age
f:public java.lang.String reflect.Person.name
================getDeclaredFields====================
f2:public java.lang.String reflect.Student.desc
f2:private int reflect.Student.score
field2:public java.lang.String reflect.Student.desc
*/
}
class Person{
public int age;
public String name;
//省略set和get方法
}
class Student extends Person{
public String desc;
private int score;
//省略set和get方法
}
上述方法需要注意的是,如果我们不期望获取其父类的字段,则需使用Class类的getDeclaredField/getDeclaredFields方法来获取字段即可,倘若需要连带获取到父类的字段,那么请使用Class类的getField/getFields,但是也只能获取到public修饰的的字段,无法获取父类的私有字段。下面将通过Field类本身的方法对指定类属性赋值,代码演示如下:
//获取Class对象引用
Class<?> clazz = Class.forName("reflect.Student");
Student st= (Student) clazz.newInstance();
//获取父类public字段并赋值
Field ageField = clazz.getField("age");
ageField.set(st,18);
Field nameField = clazz.getField("name");
nameField.set(st,"Lily");
//只获取当前类的字段,不获取父类的字段
Field descField = clazz.getDeclaredField("desc");
descField.set(st,"I am student");
Field scoreField = clazz.getDeclaredField("score");
//设置可访问,score是private的
scoreField.setAccessible(true);
scoreField.set(st,88);
System.out.println(st.toString());
//输出结果:Student{age=18, name='Lily ,desc='I am student', score=88}
//获取字段值
System.out.println(scoreField.get(st));
// 88
其中的set(Object obj, Object value)方法是Field类本身的方法,用于设置字段的值,而get(Object obj)则是获取字段的值,当然关于Field类还有其他常用的方法如下:
| 方法返回值 | 方法名称 | 方法说明 |
|---|---|---|
| void | set(Object obj, Object value) | 将指定对象变量上此 Field 对象表示的字段设置为指定的新值。 |
| Object | get(Object obj) | 返回指定对象上此 Field 表示的字段的值 |
Class<?> | getType() | 返回一个 Class 对象,它标识了此Field 对象所表示字段的声明类型。 |
| boolean | isEnumConstant() | 如果此字段表示枚举类型的元素则返回 true;否则返回 false |
| String | toGenericString() | 返回一个描述此 Field(包括其一般类型)的字符串 |
| String | getName() | 返回此 Field 对象表示的字段的名称 |
Class<?> | getDeclaringClass() | 返回表示类或接口的 Class 对象,该类或接口声明由此 Field 对象表示的字段 |
| void | setAccessible(boolean flag) | 将此对象的 accessible 标志设置为指示的布尔值,即设置其可访问性 |
上述方法可能是较为常用的,事实上在设置值的方法上,Field类还提供了专门针对基本数据类型的方法,如setInt()/getInt()、setBoolean()/getBoolean、setChar()/getChar()等等方法,这里就不全部列出了,需要时查API文档即可。需要特别注意的是被final关键字修饰的Field字段是安全的,在运行时可以接收任何修改,但最终其实际值是不会发生改变的。
Method类及其用法
Method 提供关于类或接口上单独某个方法(以及如何访问该方法)的信息,所反映的方法可能是类方法或实例方法(包括抽象方法)。
下面是Class类获取Method对象相关的方法:
| 方法返回值 | 方法名称 | 方法说明 |
|---|---|---|
| Method | getDeclaredMethod(String name, Class<?>... parameterTypes) | 返回一个指定参数的Method对象,该对象反映此 Class 对象所表示的类或接口的指定已声明方法。 |
| Method[] | getDeclaredMethods() | 返回 Method 对象的一个数组,这些对象反映此 Class 对象表示的类或接口声明的所有方法,包括公共、保护、默认(包)访问和私有方法,但不包括继承的方法。 |
| Method | getMethod(String name, Class<?>... parameterTypes) | 返回一个 Method 对象,它反映此 Class 对象所表示的类或接口的指定公共成员方法。 |
| Method[] | getMethods() | 返回一个包含某些 Method 对象的数组,这些对象反映此 Class 对象所表示的类或接口(包括那些由该类或接口声明的以及从超类和超接口继承的那些的类或接口)的公共 member 方法。 |
同样通过案例演示上述方法:
import java.lang.reflect.Method;
public class ReflectMethod {
public static void main(String[] args) throws ClassNotFoundException, NoSuchMethodException {
Class clazz = Class.forName("reflect.Circle");
//根据参数获取public的Method,包含继承自父类的方法
Method method = clazz.getMethod("draw",int.class,String.class);
System.out.println("method:"+method);
//获取所有public的方法:
Method[] methods =clazz.getMethods();
for (Method m:methods){
System.out.println("m::"+m);
}
System.out.println("=========================================");
//获取当前类的方法包含private,该方法无法获取继承自父类的method
Method method1 = clazz.getDeclaredMethod("drawCircle");
System.out.println("method1::"+method1);
//获取当前类的所有方法包含private,该方法无法获取继承自父类的method
Method[] methods1=clazz.getDeclaredMethods();
for (Method m:methods1){
System.out.println("m1::"+m);
}
}
}
class Shape {
public void draw(){
System.out.println("draw");
}
public void draw(int count , String name){
System.out.println("draw "+ name +",count="+count);
}
}
class Circle extends Shape{
private void drawCircle(){
System.out.println("drawCircle");
}
public int getAllCount(){
return 100;
}
}
输出结果:
method:public void reflect.Shape.draw(int,java.lang.String)
m::public int reflect.Circle.getAllCount()
m::public void reflect.Shape.draw()
m::public void reflect.Shape.draw(int,java.lang.String)
m::public final void java.lang.Object.wait(long,int) throws java.lang.InterruptedException
m::public final native void java.lang.Object.wait(long) throws java.lang.InterruptedException
m::public final void java.lang.Object.wait() throws java.lang.InterruptedException
m::public boolean java.lang.Object.equals(java.lang.Object)
m::public java.lang.String java.lang.Object.toString()
m::public native int java.lang.Object.hashCode()
m::public final native java.lang.Class java.lang.Object.getClass()
m::public final native void java.lang.Object.notify()
m::public final native void java.lang.Object.notifyAll()
=========================================
method1::private void reflect.Circle.drawCircle()
m1::public int reflect.Circle.getAllCount()
m1::private void reflect.Circle.drawCircle()
在通过getMethods方法获取Method对象时,会把父类的方法也获取到,如上的输出结果,把Object类的方法都打印出来了。而getDeclaredMethod/getDeclaredMethods方法都只能获取当前类的方法。我们在使用时根据情况选择即可。下面将演示通过Method对象调用指定类的方法:
Class clazz = Class.forName("reflect.Circle");
//创建对象
Circle circle = (Circle) clazz.newInstance();
//获取指定参数的方法对象Method
Method method = clazz.getMethod("draw",int.class,String.class);
//通过Method对象的invoke(Object obj,Object... args)方法调用
method.invoke(circle,15,"圈圈");
//对私有无参方法的操作
Method method1 = clazz.getDeclaredMethod("drawCircle");
//修改私有方法的访问标识
method1.setAccessible(true);
method1.invoke(circle);
//对有返回值得方法操作
Method method2 =clazz.getDeclaredMethod("getAllCount");
Integer count = (Integer) method2.invoke(circle);
System.out.println("count:"+count);
输出结果
draw 圈圈,count=15
drawCircle
count:100
在上述代码中调用方法,使用了Method类的invoke(Object obj,Object... args)第一个参数代表调用的对象,第二个参数传递的调用方法的参数。这样就完成了类方法的动态调用。
| 方法返回值 | 方法名称 | 方法说明 |
|---|---|---|
| Object | invoke(Object obj, Object... args) | 对带有指定参数的指定对象调用由此 Method 对象表示的底层方法。 |
Class<?> | getReturnType() | 返回一个 Class 对象,该对象描述了此 Method 对象所表示的方法的正式返回类型,即方法的返回类型 |
| Type | getGenericReturnType() | 返回表示由此 Method 对象所表示方法的正式返回类型的 Type 对象,也是方法的返回类型。 |
Class<?>[] | getParameterTypes() | 按照声明顺序返回 Class 对象的数组,这些对象描述了此 Method 对象所表示的方法的形参类型。即返回方法的参数类型组成的数组 |
| Type[] | getGenericParameterTypes() | 按照声明顺序返回 Type 对象的数组,这些对象描述了此 Method 对象所表示的方法的形参类型的,也是返回方法的参数类型 |
| String | getName() | 以 String 形式返回此 Method 对象表示的方法名称,即返回方法的名称 |
| boolean | isVarArgs() | 判断方法是否带可变参数,如果将此方法声明为带有可变数量的参数,则返回 true;否则,返回 false。 |
| String | toGenericString() | 返回描述此 Method 的字符串,包括类型参数。 |
getReturnType方法/getGenericReturnType方法都是获取Method对象表示的方法的返回类型,只不过前者返回的Class类型后者返回的Type(前面已分析过),Type就是一个接口而已,在Java8中新增一个默认的方法实现,返回的就参数类型信息
public interface Type {
//1.8新增
default String getTypeName() {
return toString();
}
}
而getParameterTypes/getGenericParameterTypes也是同样的道理,都是获取Method对象所表示的方法的参数类型,其他方法与前面的Field和Constructor是类似的。
反射机制执行的流程
先看个例子
public class HelloReflect {
public static void main(String[] args) {
try {
// 1. 使用外部配置的实现,进行动态加载类
TempFunctionTest test = (TempFunctionTest)Class.forName("com.tester.HelloReflect").newInstance();
test.sayHello("call directly");
// 2. 根据配置的函数名,进行方法调用(不需要通用的接口抽象)
Object t2 = new TempFunctionTest();
Method method = t2.getClass().getDeclaredMethod("sayHello", String.class);
method.invoke(test, "method invoke");
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (InstantiationException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (NoSuchMethodException e ) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
}
public void sayHello(String word) {
System.out.println("hello," + word);
}
}
来看执行流程
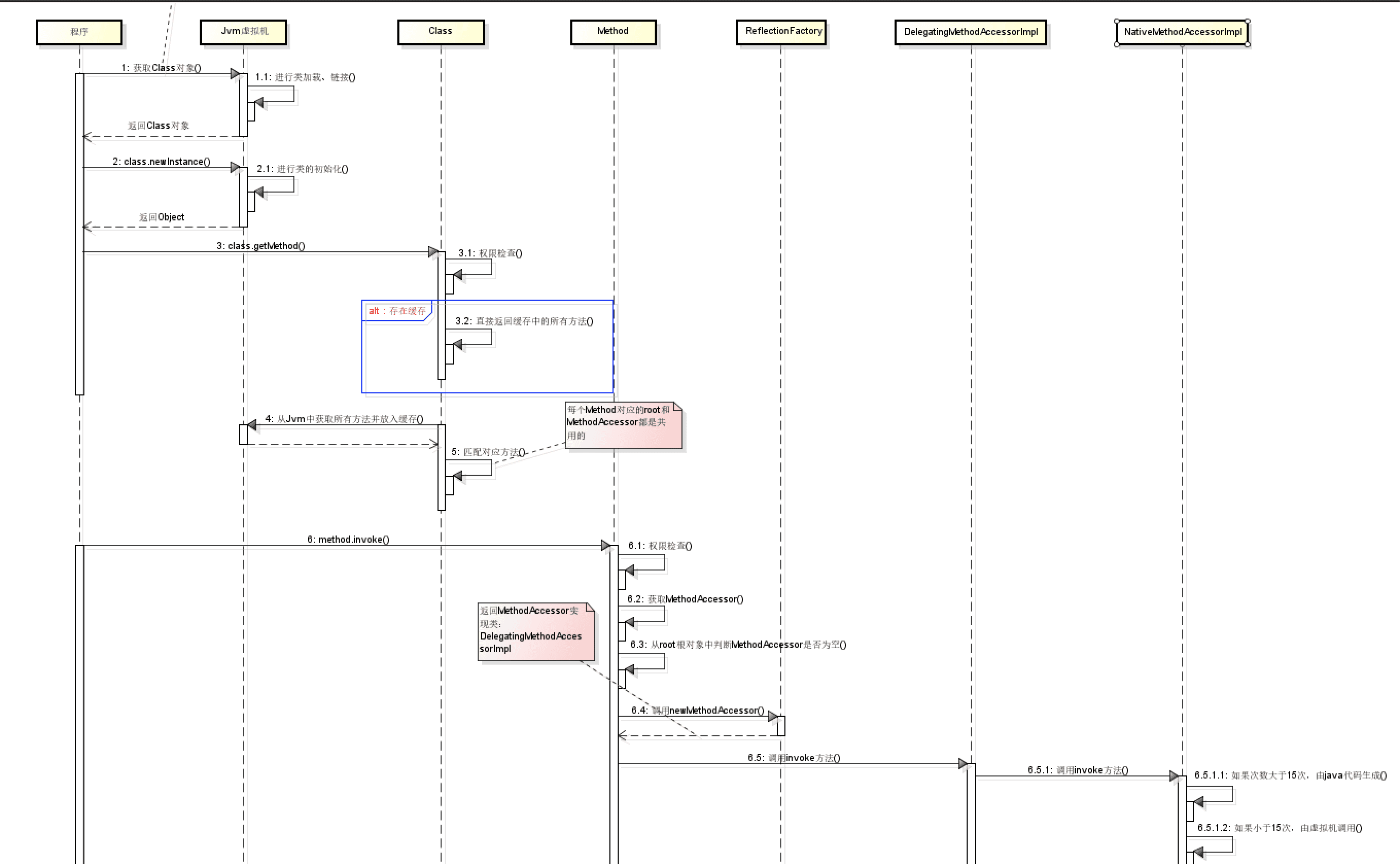
反射获取类实例
首先调用了 java.lang.Class 的静态方法,获取类信息。
@CallerSensitive
public static Class<?> forName(String className)
throws ClassNotFoundException {
// 先通过反射,获取调用进来的类信息,从而获取当前的 classLoader
Class<?> caller = Reflection.getCallerClass();
// 调用native方法进行获取class信息
return forName0(className, true, ClassLoader.getClassLoader(caller), caller);
}
forName()反射获取类信息,并没有将实现留给了java,而是交给了jvm去加载。
主要是先获取 ClassLoader, 然后调用 native 方法,获取信息,加载类则是回调 java.lang.ClassLoader.
最后,jvm又会回调 ClassLoader 进类加载。
//
public Class<?> loadClass(String name) throws ClassNotFoundException {
return loadClass(name, false);
}
// sun.misc.Launcher
public Class<?> loadClass(String var1, boolean var2) throws ClassNotFoundException {
int var3 = var1.lastIndexOf(46);
if(var3 != -1) {
SecurityManager var4 = System.getSecurityManager();
if(var4 != null) {
var4.checkPackageAccess(var1.substring(0, var3));
}
}
if(this.ucp.knownToNotExist(var1)) {
Class var5 = this.findLoadedClass(var1);
if(var5 != null) {
if(var2) {
this.resolveClass(var5);
}
return var5;
} else {
throw new ClassNotFoundException(var1);
}
} else {
return super.loadClass(var1, var2);
}
}
// java.lang.ClassLoader
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
// 先获取锁
synchronized (getClassLoadingLock(name)) {
// First, check if the class has already been loaded
// 如果已经加载了的话,就不用再加载了
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
// 双亲委托加载
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
// 父类没有加载到时,再自己加载
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
protected Object getClassLoadingLock(String className) {
Object lock = this;
if (parallelLockMap != null) {
// 使用 ConcurrentHashMap来保存锁
Object newLock = new Object();
lock = parallelLockMap.putIfAbsent(className, newLock);
if (lock == null) {
lock = newLock;
}
}
return lock;
}
protected final Class<?> findLoadedClass(String name) {
if (!checkName(name))
return null;
return findLoadedClass0(name);
}
下面来看一下 newInstance() 的实现方式。
// 首先肯定是 Class.newInstance
@CallerSensitive
public T newInstance()
throws InstantiationException, IllegalAccessException
{
if (System.getSecurityManager() != null) {
checkMemberAccess(Member.PUBLIC, Reflection.getCallerClass(), false);
}
// NOTE: the following code may not be strictly correct under
// the current Java memory model.
// Constructor lookup
// newInstance() 其实相当于调用类的无参构造函数,所以,首先要找到其无参构造器
if (cachedConstructor == null) {
if (this == Class.class) {
// 不允许调用 Class 的 newInstance() 方法
throw new IllegalAccessException(
"Can not call newInstance() on the Class for java.lang.Class"
);
}
try {
// 获取无参构造器
Class<?>[] empty = {};
final Constructor<T> c = getConstructor0(empty, Member.DECLARED);
// Disable accessibility checks on the constructor
// since we have to do the security check here anyway
// (the stack depth is wrong for the Constructor's
// security check to work)
java.security.AccessController.doPrivileged(
new java.security.PrivilegedAction<Void>() {
public Void run() {
c.setAccessible(true);
return null;
}
});
cachedConstructor = c;
} catch (NoSuchMethodException e) {
throw (InstantiationException)
new InstantiationException(getName()).initCause(e);
}
}
Constructor<T> tmpConstructor = cachedConstructor;
// Security check (same as in java.lang.reflect.Constructor)
int modifiers = tmpConstructor.getModifiers();
if (!Reflection.quickCheckMemberAccess(this, modifiers)) {
Class<?> caller = Reflection.getCallerClass();
if (newInstanceCallerCache != caller) {
Reflection.ensureMemberAccess(caller, this, null, modifiers);
newInstanceCallerCache = caller;
}
}
// Run constructor
try {
// 调用无参构造器
return tmpConstructor.newInstance((Object[])null);
} catch (InvocationTargetException e) {
Unsafe.getUnsafe().throwException(e.getTargetException());
// Not reached
return null;
}
}
newInstance() 主要做了三件事:
-
- 权限检测,如果不通过直接抛出异常;
-
- 查找无参构造器,并将其缓存起来;
-
- 调用具体方法的无参构造方法,生成实例并返回;
下面是获取构造器的过程:
private Constructor<T> getConstructor0(Class<?>[] parameterTypes,
int which) throws NoSuchMethodException
{
// 获取所有构造器
Constructor<T>[] constructors = privateGetDeclaredConstructors((which == Member.PUBLIC));
for (Constructor<T> constructor : constructors) {
if (arrayContentsEq(parameterTypes,
constructor.getParameterTypes())) {
return getReflectionFactory().copyConstructor(constructor);
}
}
throw new NoSuchMethodException(getName() + ".<init>" + argumentTypesToString(parameterTypes));
}
getConstructor0() 为获取匹配的构造方器;分三步:
-
- 先获取所有的constructors, 然后通过进行参数类型比较;
-
- 找到匹配后,通过 ReflectionFactory copy一份constructor返回;
-
- 否则抛出 NoSuchMethodException;
// 获取当前类所有的构造方法,通过jvm或者缓存
// Returns an array of "root" constructors. These Constructor
// objects must NOT be propagated to the outside world, but must
// instead be copied via ReflectionFactory.copyConstructor.
private Constructor<T>[] privateGetDeclaredConstructors(boolean publicOnly) {
checkInitted();
Constructor<T>[] res;
// 调用 reflectionData(), 获取保存的信息,使用软引用保存,从而使内存不够可以回收
ReflectionData<T> rd = reflectionData();
if (rd != null) {
res = publicOnly ? rd.publicConstructors : rd.declaredConstructors;
// 存在缓存,则直接返回
if (res != null) return res;
}
// No cached value available; request value from VM
if (isInterface()) {
@SuppressWarnings("unchecked")
Constructor<T>[] temporaryRes = (Constructor<T>[]) new Constructor<?>[0];
res = temporaryRes;
} else {
// 使用native方法从jvm获取构造器
res = getDeclaredConstructors0(publicOnly);
}
if (rd != null) {
// 最后,将从jvm中读取的内容,存入缓存
if (publicOnly) {
rd.publicConstructors = res;
} else {
rd.declaredConstructors = res;
}
}
return res;
}
// Lazily create and cache ReflectionData
private ReflectionData<T> reflectionData() {
SoftReference<ReflectionData<T>> reflectionData = this.reflectionData;
int classRedefinedCount = this.classRedefinedCount;
ReflectionData<T> rd;
if (useCaches &&
reflectionData != null &&
(rd = reflectionData.get()) != null &&
rd.redefinedCount == classRedefinedCount) {
return rd;
}
// else no SoftReference or cleared SoftReference or stale ReflectionData
// -> create and replace new instance
return newReflectionData(reflectionData, classRedefinedCount);
}
// 新创建缓存,保存反射信息
private ReflectionData<T> newReflectionData(SoftReference<ReflectionData<T>> oldReflectionData,
int classRedefinedCount) {
if (!useCaches) return null;
// 使用cas保证更新的线程安全性,所以反射是保证线程安全的
while (true) {
ReflectionData<T> rd = new ReflectionData<>(classRedefinedCount);
// try to CAS it...
if (Atomic.casReflectionData(this, oldReflectionData, new SoftReference<>(rd))) {
return rd;
}
// 先使用CAS更新,如果更新成功,则立即返回,否则测查当前已被其他线程更新的情况,如果和自己想要更新的状态一致,则也算是成功了
oldReflectionData = this.reflectionData;
classRedefinedCount = this.classRedefinedCount;
if (oldReflectionData != null &&
(rd = oldReflectionData.get()) != null &&
rd.redefinedCount == classRedefinedCount) {
return rd;
}
}
}
如上,privateGetDeclaredConstructors(), 获取所有的构造器主要步骤;
-
- 先尝试从缓存中获取;
-
- 如果缓存没有,则从jvm中重新获取,并存入缓存,缓存使用软引用进行保存,保证内存可用;
另外,使用 relactionData() 进行缓存保存;ReflectionData 的数据结构如下。
// reflection data that might get invalidated when JVM TI RedefineClasses() is called
private static class ReflectionData<T> {
volatile Field[] declaredFields;
volatile Field[] publicFields;
volatile Method[] declaredMethods;
volatile Method[] publicMethods;
volatile Constructor<T>[] declaredConstructors;
volatile Constructor<T>[] publicConstructors;
// Intermediate results for getFields and getMethods
volatile Field[] declaredPublicFields;
volatile Method[] declaredPublicMethods;
volatile Class<?>[] interfaces;
// Value of classRedefinedCount when we created this ReflectionData instance
final int redefinedCount;
ReflectionData(int redefinedCount) {
this.redefinedCount = redefinedCount;
}
}
其中,还有一个点,就是如何比较构造是否是要查找构造器,其实就是比较类型完成相等就完了,有一个不相等则返回false。
private static boolean arrayContentsEq(Object[] a1, Object[] a2) {
if (a1 == null) {
return a2 == null || a2.length == 0;
}
if (a2 == null) {
return a1.length == 0;
}
if (a1.length != a2.length) {
return false;
}
for (int i = 0; i < a1.length; i++) {
if (a1[i] != a2[i]) {
return false;
}
}
return true;
}
// sun.reflect.ReflectionFactory
/** Makes a copy of the passed constructor. The returned
constructor is a "child" of the passed one; see the comments
in Constructor.java for details. */
public <T> Constructor<T> copyConstructor(Constructor<T> arg) {
return langReflectAccess().copyConstructor(arg);
}
// java.lang.reflect.Constructor, copy 其实就是新new一个 Constructor 出来
Constructor<T> copy() {
// This routine enables sharing of ConstructorAccessor objects
// among Constructor objects which refer to the same underlying
// method in the VM. (All of this contortion is only necessary
// because of the "accessibility" bit in AccessibleObject,
// which implicitly requires that new java.lang.reflect
// objects be fabricated for each reflective call on Class
// objects.)
if (this.root != null)
throw new IllegalArgumentException("Can not copy a non-root Constructor");
Constructor<T> res = new Constructor<>(clazz,
parameterTypes,
exceptionTypes, modifiers, slot,
signature,
annotations,
parameterAnnotations);
// root 指向当前 constructor
res.root = this;
// Might as well eagerly propagate this if already present
res.constructorAccessor = constructorAccessor;
return res;
}
通过上面,获取到 Constructor 了。
接下来就只需调用其相应构造器的 newInstance(),即返回实例了。
// return tmpConstructor.newInstance((Object[])null);
// java.lang.reflect.Constructor
@CallerSensitive
public T newInstance(Object ... initargs)
throws InstantiationException, IllegalAccessException,
IllegalArgumentException, InvocationTargetException
{
if (!override) {
if (!Reflection.quickCheckMemberAccess(clazz, modifiers)) {
Class<?> caller = Reflection.getCallerClass();
checkAccess(caller, clazz, null, modifiers);
}
}
if ((clazz.getModifiers() & Modifier.ENUM) != 0)
throw new IllegalArgumentException("Cannot reflectively create enum objects");
ConstructorAccessor ca = constructorAccessor; // read volatile
if (ca == null) {
ca = acquireConstructorAccessor();
}
@SuppressWarnings("unchecked")
T inst = (T) ca.newInstance(initargs);
return inst;
}
// sun.reflect.DelegatingConstructorAccessorImpl
public Object newInstance(Object[] args)
throws InstantiationException,
IllegalArgumentException,
InvocationTargetException
{
return delegate.newInstance(args);
}
// sun.reflect.NativeConstructorAccessorImpl
public Object newInstance(Object[] args)
throws InstantiationException,
IllegalArgumentException,
InvocationTargetException
{
// We can't inflate a constructor belonging to a vm-anonymous class
// because that kind of class can't be referred to by name, hence can't
// be found from the generated bytecode.
if (++numInvocations > ReflectionFactory.inflationThreshold()
&& !ReflectUtil.isVMAnonymousClass(c.getDeclaringClass())) {
ConstructorAccessorImpl acc = (ConstructorAccessorImpl)
new MethodAccessorGenerator().
generateConstructor(c.getDeclaringClass(),
c.getParameterTypes(),
c.getExceptionTypes(),
c.getModifiers());
parent.setDelegate(acc);
}
// 调用native方法,进行调用 constructor
return newInstance0(c, args);
}
返回构造器的实例后,可以根据外部进行进行类型转换,从而使用接口或方法进行调用实例功能了。
反射获取方法
- 第一步,先获取 Method;
// java.lang.Class
@CallerSensitive
public Method getDeclaredMethod(String name, Class<?>... parameterTypes)
throws NoSuchMethodException, SecurityException {
checkMemberAccess(Member.DECLARED, Reflection.getCallerClass(), true);
Method method = searchMethods(privateGetDeclaredMethods(false), name, parameterTypes);
if (method == null) {
throw new NoSuchMethodException(getName() + "." + name + argumentTypesToString(parameterTypes));
}
return method;
}
忽略第一个检查权限,剩下就只有两个动作了。
-
- 获取所有方法列表;
-
- 根据方法名称和方法列表,选出符合要求的方法;
-
- 如果没有找到相应方法,抛出异常,否则返回对应方法;
所以,先看一下怎样获取类声明的所有方法?
// Returns an array of "root" methods. These Method objects must NOT
// be propagated to the outside world, but must instead be copied
// via ReflectionFactory.copyMethod.
private Method[] privateGetDeclaredMethods(boolean publicOnly) {
checkInitted();
Method[] res;
ReflectionData<T> rd = reflectionData();
if (rd != null) {
res = publicOnly ? rd.declaredPublicMethods : rd.declaredMethods;
if (res != null) return res;
}
// No cached value available; request value from VM
res = Reflection.filterMethods(this, getDeclaredMethods0(publicOnly));
if (rd != null) {
if (publicOnly) {
rd.declaredPublicMethods = res;
} else {
rd.declaredMethods = res;
}
}
return res;
}
很相似,和获取所有构造器的方法很相似,都是先从缓存中获取方法,如果没有,则从jvm中获取。
不同的是,方法列表需要进行过滤 Reflection.filterMethods;当然后面看来,这个方法我们一般不会派上用场。
// sun.misc.Reflection
public static Method[] filterMethods(Class<?> containingClass, Method[] methods) {
if (methodFilterMap == null) {
// Bootstrapping
return methods;
}
return (Method[])filter(methods, methodFilterMap.get(containingClass));
}
// 可以过滤指定的方法,一般为空,如果要指定过滤,可以调用 registerMethodsToFilter(), 或者...
private static Member[] filter(Member[] members, String[] filteredNames) {
if ((filteredNames == null) || (members.length == 0)) {
return members;
}
int numNewMembers = 0;
for (Member member : members) {
boolean shouldSkip = false;
for (String filteredName : filteredNames) {
if (member.getName() == filteredName) {
shouldSkip = true;
break;
}
}
if (!shouldSkip) {
++numNewMembers;
}
}
Member[] newMembers =
(Member[])Array.newInstance(members[0].getClass(), numNewMembers);
int destIdx = 0;
for (Member member : members) {
boolean shouldSkip = false;
for (String filteredName : filteredNames) {
if (member.getName() == filteredName) {
shouldSkip = true;
break;
}
}
if (!shouldSkip) {
newMembers[destIdx++] = member;
}
}
return newMembers;
}
- 第二步,根据方法名和参数类型过滤指定方法返回:
private static Method searchMethods(Method[] methods,
String name,
Class<?>[] parameterTypes)
{
Method res = null;
// 使用常量池,避免重复创建String
String internedName = name.intern();
for (int i = 0; i < methods.length; i++) {
Method m = methods[i];
if (m.getName() == internedName
&& arrayContentsEq(parameterTypes, m.getParameterTypes())
&& (res == null
|| res.getReturnType().isAssignableFrom(m.getReturnType())))
res = m;
}
return (res == null ? res : getReflectionFactory().copyMethod(res));
}
大概意思看得明白,就是匹配到方法名,然后参数类型匹配,才可以。
- 但是可以看到,匹配到一个方法,并没有退出for循环,而是继续进行匹配。
- 这里是匹配最精确的子类进行返回(最优匹配)
- 最后,还是通过 ReflectionFactory, copy 方法后返回。
调用 method.invoke() 方法
@CallerSensitive
public Object invoke(Object obj, Object... args)
throws IllegalAccessException, IllegalArgumentException,
InvocationTargetException
{
if (!override) {
if (!Reflection.quickCheckMemberAccess(clazz, modifiers)) {
Class<?> caller = Reflection.getCallerClass();
checkAccess(caller, clazz, obj, modifiers);
}
}
MethodAccessor ma = methodAccessor; // read volatile
if (ma == null) {
ma = acquireMethodAccessor();
}
return ma.invoke(obj, args);
}
invoke时,是通过 MethodAccessor 进行调用的,而 MethodAccessor 是个接口,在第一次时调用 acquireMethodAccessor() 进行新创建。
// probably make the implementation more scalable.
private MethodAccessor acquireMethodAccessor() {
// First check to see if one has been created yet, and take it
// if so
MethodAccessor tmp = null;
if (root != null) tmp = root.getMethodAccessor();
if (tmp != null) {
// 存在缓存时,存入 methodAccessor,否则调用 ReflectionFactory 创建新的 MethodAccessor
methodAccessor = tmp;
} else {
// Otherwise fabricate one and propagate it up to the root
tmp = reflectionFactory.newMethodAccessor(this);
setMethodAccessor(tmp);
}
return tmp;
}
// sun.reflect.ReflectionFactory
public MethodAccessor newMethodAccessor(Method method) {
checkInitted();
if (noInflation && !ReflectUtil.isVMAnonymousClass(method.getDeclaringClass())) {
return new MethodAccessorGenerator().
generateMethod(method.getDeclaringClass(),
method.getName(),
method.getParameterTypes(),
method.getReturnType(),
method.getExceptionTypes(),
method.getModifiers());
} else {
NativeMethodAccessorImpl acc =
new NativeMethodAccessorImpl(method);
DelegatingMethodAccessorImpl res =
new DelegatingMethodAccessorImpl(acc);
acc.setParent(res);
return res;
}
}
两个Accessor详情:
// NativeMethodAccessorImpl / DelegatingMethodAccessorImpl
class NativeMethodAccessorImpl extends MethodAccessorImpl {
private final Method method;
private DelegatingMethodAccessorImpl parent;
private int numInvocations;
NativeMethodAccessorImpl(Method method) {
this.method = method;
}
public Object invoke(Object obj, Object[] args)
throws IllegalArgumentException, InvocationTargetException
{
// We can't inflate methods belonging to vm-anonymous classes because
// that kind of class can't be referred to by name, hence can't be
// found from the generated bytecode.
if (++numInvocations > ReflectionFactory.inflationThreshold()
&& !ReflectUtil.isVMAnonymousClass(method.getDeclaringClass())) {
MethodAccessorImpl acc = (MethodAccessorImpl)
new MethodAccessorGenerator().
generateMethod(method.getDeclaringClass(),
method.getName(),
method.getParameterTypes(),
method.getReturnType(),
method.getExceptionTypes(),
method.getModifiers());
parent.setDelegate(acc);
}
return invoke0(method, obj, args);
}
void setParent(DelegatingMethodAccessorImpl parent) {
this.parent = parent;
}
private static native Object invoke0(Method m, Object obj, Object[] args);
}
class DelegatingMethodAccessorImpl extends MethodAccessorImpl {
private MethodAccessorImpl delegate;
DelegatingMethodAccessorImpl(MethodAccessorImpl delegate) {
setDelegate(delegate);
}
public Object invoke(Object obj, Object[] args)
throws IllegalArgumentException, InvocationTargetException
{
return delegate.invoke(obj, args);
}
void setDelegate(MethodAccessorImpl delegate) {
this.delegate = delegate;
}
}
进行 ma.invoke(obj, args); 调用时,调用 DelegatingMethodAccessorImpl.invoke();
最后被委托到 NativeMethodAccessorImpl.invoke(), 即:
public Object invoke(Object obj, Object[] args)
throws IllegalArgumentException, InvocationTargetException
{
// We can't inflate methods belonging to vm-anonymous classes because
// that kind of class can't be referred to by name, hence can't be
// found from the generated bytecode.
if (++numInvocations > ReflectionFactory.inflationThreshold()
&& !ReflectUtil.isVMAnonymousClass(method.getDeclaringClass())) {
MethodAccessorImpl acc = (MethodAccessorImpl)
new MethodAccessorGenerator().
generateMethod(method.getDeclaringClass(),
method.getName(),
method.getParameterTypes(),
method.getReturnType(),
method.getExceptionTypes(),
method.getModifiers());
parent.setDelegate(acc);
}
// invoke0 是个 native 方法,由jvm进行调用业务方法。从而完成反射调用功能。
return invoke0(method, obj, args);
}
其中, generateMethod() 是生成具体类的方法:
/** This routine is not thread-safe */
public MethodAccessor generateMethod(Class<?> declaringClass,
String name,
Class<?>[] parameterTypes,
Class<?> returnType,
Class<?>[] checkedExceptions,
int modifiers)
{
return (MethodAccessor) generate(declaringClass,
name,
parameterTypes,
returnType,
checkedExceptions,
modifiers,
false,
false,
null);
}
generate() 戳详情。
/** This routine is not thread-safe */
private MagicAccessorImpl generate(final Class<?> declaringClass,
String name,
Class<?>[] parameterTypes,
Class<?> returnType,
Class<?>[] checkedExceptions,
int modifiers,
boolean isConstructor,
boolean forSerialization,
Class<?> serializationTargetClass)
{
ByteVector vec = ByteVectorFactory.create();
asm = new ClassFileAssembler(vec);
this.declaringClass = declaringClass;
this.parameterTypes = parameterTypes;
this.returnType = returnType;
this.modifiers = modifiers;
this.isConstructor = isConstructor;
this.forSerialization = forSerialization;
asm.emitMagicAndVersion();
// Constant pool entries:
// ( * = Boxing information: optional)
// (+ = Shared entries provided by AccessorGenerator)
// (^ = Only present if generating SerializationConstructorAccessor)
// [UTF-8] [This class's name]
// [CONSTANT_Class_info] for above
// [UTF-8] "sun/reflect/{MethodAccessorImpl,ConstructorAccessorImpl,SerializationConstructorAccessorImpl}"
// [CONSTANT_Class_info] for above
// [UTF-8] [Target class's name]
// [CONSTANT_Class_info] for above
// ^ [UTF-8] [Serialization: Class's name in which to invoke constructor]
// ^ [CONSTANT_Class_info] for above
// [UTF-8] target method or constructor name
// [UTF-8] target method or constructor signature
// [CONSTANT_NameAndType_info] for above
// [CONSTANT_Methodref_info or CONSTANT_InterfaceMethodref_info] for target method
// [UTF-8] "invoke" or "newInstance"
// [UTF-8] invoke or newInstance descriptor
// [UTF-8] descriptor for type of non-primitive parameter 1
// [CONSTANT_Class_info] for type of non-primitive parameter 1
// ...
// [UTF-8] descriptor for type of non-primitive parameter n
// [CONSTANT_Class_info] for type of non-primitive parameter n
// + [UTF-8] "java/lang/Exception"
// + [CONSTANT_Class_info] for above
// + [UTF-8] "java/lang/ClassCastException"
// + [CONSTANT_Class_info] for above
// + [UTF-8] "java/lang/NullPointerException"
// + [CONSTANT_Class_info] for above
// + [UTF-8] "java/lang/IllegalArgumentException"
// + [CONSTANT_Class_info] for above
// + [UTF-8] "java/lang/InvocationTargetException"
// + [CONSTANT_Class_info] for above
// + [UTF-8] "<init>"
// + [UTF-8] "()V"
// + [CONSTANT_NameAndType_info] for above
// + [CONSTANT_Methodref_info] for NullPointerException's constructor
// + [CONSTANT_Methodref_info] for IllegalArgumentException's constructor
// + [UTF-8] "(Ljava/lang/String;)V"
// + [CONSTANT_NameAndType_info] for "<init>(Ljava/lang/String;)V"
// + [CONSTANT_Methodref_info] for IllegalArgumentException's constructor taking a String
// + [UTF-8] "(Ljava/lang/Throwable;)V"
// + [CONSTANT_NameAndType_info] for "<init>(Ljava/lang/Throwable;)V"
// + [CONSTANT_Methodref_info] for InvocationTargetException's constructor
// + [CONSTANT_Methodref_info] for "super()"
// + [UTF-8] "java/lang/Object"
// + [CONSTANT_Class_info] for above
// + [UTF-8] "toString"
// + [UTF-8] "()Ljava/lang/String;"
// + [CONSTANT_NameAndType_info] for "toString()Ljava/lang/String;"
// + [CONSTANT_Methodref_info] for Object's toString method
// + [UTF-8] "Code"
// + [UTF-8] "Exceptions"
// * [UTF-8] "java/lang/Boolean"
// * [CONSTANT_Class_info] for above
// * [UTF-8] "(Z)V"
// * [CONSTANT_NameAndType_info] for above
// * [CONSTANT_Methodref_info] for above
// * [UTF-8] "booleanValue"
// * [UTF-8] "()Z"
// * [CONSTANT_NameAndType_info] for above
// * [CONSTANT_Methodref_info] for above
// * [UTF-8] "java/lang/Byte"
// * [CONSTANT_Class_info] for above
// * [UTF-8] "(B)V"
// * [CONSTANT_NameAndType_info] for above
// * [CONSTANT_Methodref_info] for above
// * [UTF-8] "byteValue"
// * [UTF-8] "()B"
// * [CONSTANT_NameAndType_info] for above
// * [CONSTANT_Methodref_info] for above
// * [UTF-8] "java/lang/Character"
// * [CONSTANT_Class_info] for above
// * [UTF-8] "(C)V"
// * [CONSTANT_NameAndType_info] for above
// * [CONSTANT_Methodref_info] for above
// * [UTF-8] "charValue"
// * [UTF-8] "()C"
// * [CONSTANT_NameAndType_info] for above
// * [CONSTANT_Methodref_info] for above
// * [UTF-8] "java/lang/Double"
// * [CONSTANT_Class_info] for above
// * [UTF-8] "(D)V"
// * [CONSTANT_NameAndType_info] for above
// * [CONSTANT_Methodref_info] for above
// * [UTF-8] "doubleValue"
// * [UTF-8] "()D"
// * [CONSTANT_NameAndType_info] for above
// * [CONSTANT_Methodref_info] for above
// * [UTF-8] "java/lang/Float"
// * [CONSTANT_Class_info] for above
// * [UTF-8] "(F)V"
// * [CONSTANT_NameAndType_info] for above
// * [CONSTANT_Methodref_info] for above
// * [UTF-8] "floatValue"
// * [UTF-8] "()F"
// * [CONSTANT_NameAndType_info] for above
// * [CONSTANT_Methodref_info] for above
// * [UTF-8] "java/lang/Integer"
// * [CONSTANT_Class_info] for above
// * [UTF-8] "(I)V"
// * [CONSTANT_NameAndType_info] for above
// * [CONSTANT_Methodref_info] for above
// * [UTF-8] "intValue"
// * [UTF-8] "()I"
// * [CONSTANT_NameAndType_info] for above
// * [CONSTANT_Methodref_info] for above
// * [UTF-8] "java/lang/Long"
// * [CONSTANT_Class_info] for above
// * [UTF-8] "(J)V"
// * [CONSTANT_NameAndType_info] for above
// * [CONSTANT_Methodref_info] for above
// * [UTF-8] "longValue"
// * [UTF-8] "()J"
// * [CONSTANT_NameAndType_info] for above
// * [CONSTANT_Methodref_info] for above
// * [UTF-8] "java/lang/Short"
// * [CONSTANT_Class_info] for above
// * [UTF-8] "(S)V"
// * [CONSTANT_NameAndType_info] for above
// * [CONSTANT_Methodref_info] for above
// * [UTF-8] "shortValue"
// * [UTF-8] "()S"
// * [CONSTANT_NameAndType_info] for above
// * [CONSTANT_Methodref_info] for above
short numCPEntries = NUM_BASE_CPOOL_ENTRIES + NUM_COMMON_CPOOL_ENTRIES;
boolean usesPrimitives = usesPrimitiveTypes();
if (usesPrimitives) {
numCPEntries += NUM_BOXING_CPOOL_ENTRIES;
}
if (forSerialization) {
numCPEntries += NUM_SERIALIZATION_CPOOL_ENTRIES;
}
// Add in variable-length number of entries to be able to describe
// non-primitive parameter types and checked exceptions.
numCPEntries += (short) (2 * numNonPrimitiveParameterTypes());
asm.emitShort(add(numCPEntries, S1));
final String generatedName = generateName(isConstructor, forSerialization);
asm.emitConstantPoolUTF8(generatedName);
asm.emitConstantPoolClass(asm.cpi());
thisClass = asm.cpi();
if (isConstructor) {
if (forSerialization) {
asm.emitConstantPoolUTF8
("sun/reflect/SerializationConstructorAccessorImpl");
} else {
asm.emitConstantPoolUTF8("sun/reflect/ConstructorAccessorImpl");
}
} else {
asm.emitConstantPoolUTF8("sun/reflect/MethodAccessorImpl");
}
asm.emitConstantPoolClass(asm.cpi());
superClass = asm.cpi();
asm.emitConstantPoolUTF8(getClassName(declaringClass, false));
asm.emitConstantPoolClass(asm.cpi());
targetClass = asm.cpi();
short serializationTargetClassIdx = (short) 0;
if (forSerialization) {
asm.emitConstantPoolUTF8(getClassName(serializationTargetClass, false));
asm.emitConstantPoolClass(asm.cpi());
serializationTargetClassIdx = asm.cpi();
}
asm.emitConstantPoolUTF8(name);
asm.emitConstantPoolUTF8(buildInternalSignature());
asm.emitConstantPoolNameAndType(sub(asm.cpi(), S1), asm.cpi());
if (isInterface()) {
asm.emitConstantPoolInterfaceMethodref(targetClass, asm.cpi());
} else {
if (forSerialization) {
asm.emitConstantPoolMethodref(serializationTargetClassIdx, asm.cpi());
} else {
asm.emitConstantPoolMethodref(targetClass, asm.cpi());
}
}
targetMethodRef = asm.cpi();
if (isConstructor) {
asm.emitConstantPoolUTF8("newInstance");
} else {
asm.emitConstantPoolUTF8("invoke");
}
invokeIdx = asm.cpi();
if (isConstructor) {
asm.emitConstantPoolUTF8("([Ljava/lang/Object;)Ljava/lang/Object;");
} else {
asm.emitConstantPoolUTF8
("(Ljava/lang/Object;[Ljava/lang/Object;)Ljava/lang/Object;");
}
invokeDescriptorIdx = asm.cpi();
// Output class information for non-primitive parameter types
nonPrimitiveParametersBaseIdx = add(asm.cpi(), S2);
for (int i = 0; i < parameterTypes.length; i++) {
Class<?> c = parameterTypes[i];
if (!isPrimitive(c)) {
asm.emitConstantPoolUTF8(getClassName(c, false));
asm.emitConstantPoolClass(asm.cpi());
}
}
// Entries common to FieldAccessor, MethodAccessor and ConstructorAccessor
emitCommonConstantPoolEntries();
// Boxing entries
if (usesPrimitives) {
emitBoxingContantPoolEntries();
}
if (asm.cpi() != numCPEntries) {
throw new InternalError("Adjust this code (cpi = " + asm.cpi() +
", numCPEntries = " + numCPEntries + ")");
}
// Access flags
asm.emitShort(ACC_PUBLIC);
// This class
asm.emitShort(thisClass);
// Superclass
asm.emitShort(superClass);
// Interfaces count and interfaces
asm.emitShort(S0);
// Fields count and fields
asm.emitShort(S0);
// Methods count and methods
asm.emitShort(NUM_METHODS);
emitConstructor();
emitInvoke();
// Additional attributes (none)
asm.emitShort(S0);
// Load class
vec.trim();
final byte[] bytes = vec.getData();
// Note: the class loader is the only thing that really matters
// here -- it's important to get the generated code into the
// same namespace as the target class. Since the generated code
// is privileged anyway, the protection domain probably doesn't
// matter.
return AccessController.doPrivileged(
new PrivilegedAction<MagicAccessorImpl>() {
public MagicAccessorImpl run() {
try {
return (MagicAccessorImpl)
ClassDefiner.defineClass
(generatedName,
bytes,
0,
bytes.length,
declaringClass.getClassLoader()).newInstance();
} catch (InstantiationException | IllegalAccessException e) {
throw new InternalError(e);
}
}
});
}
咱们主要看这一句:ClassDefiner.defineClass(xx, declaringClass.getClassLoader()).newInstance();
在ClassDefiner.defineClass方法实现中,每被调用一次都会生成一个DelegatingClassLoader类加载器对象 ,这里每次都生成新的类加载器,是为了性能考虑,在某些情况下可以卸载这些生成的类,因为类的卸载是只有在类加载器可以被回收的情况下才会被回收的,如果用了原来的类加载器,那可能导致这些新创建的类一直无法被卸载。
而反射生成的类,有时候可能用了就可以卸载了,所以使用其独立的类加载器,从而使得更容易控制反射类的生命周期。
反射调用流程小结
最后,用几句话总结反射的实现原理:
- 反射类及反射方法的获取,都是通过从列表中搜寻查找匹配的方法,所以查找性能会随类的大小方法多少而变化;
- 每个类都会有一个与之对应的Class实例,从而每个类都可以获取method反射方法,并作用到其他实例身上;
- 反射也是考虑了线程安全的,放心使用;
- 反射使用软引用relectionData缓存class信息,避免每次重新从jvm获取带来的开销;
- 反射调用多次生成新代理Accessor, 而通过字节码生存的则考虑了卸载功能,所以会使用独立的类加载器;
- 当找到需要的方法,都会copy一份出来,而不是使用原来的实例,从而保证数据隔离;
- 调度反射方法,最终是由jvm执行invoke0()执行;